深度学习学习率调整方案如何选择?
发布时间:2024-07-11 18:18:43 浏览次数:
现在深度学习有很多种学习率调整方案,比如SGD,Adagrad,Adadelta,Adam,Adamax,Nadam。。。在pytorch的lr_scheduler中,还有LambdaLR,StepLR,MultiStepLR,ExponentialLR,CosineAnnealingLR,ReduceLROnPlateau。
问题一,哪一种优化器在大的模型上性能好?亦或是不同的模型情况会不一样?
问题二,比如Adam可以动态调整学习率,装进lr_scheduler不会有冲突吗?它们是如何共同工作的?
问题三,哪一种lr_scheduler在大的模型上性能好?亦或是不同的模型情况会不一样?
选优化器是一个问题,选LR scheduler是另一个问题。两者不可混为一谈。
最基本的建议,选择你的领域里那些常用的优化器和LR Scheduler。
问题一:,哪一种优化器在大的模型上性能好?亦或是不同的模型情况会不一样?
回答一:和模型大小关系不大,和模型类型关系很大。大体情况是,计算机视觉优先使用SGD(with Momentum),NLP(特别是用Transformer)优先使用Adam(或其他Adam variants)。
这是两个最通用、最基本的选择。
如果你在计算机视觉里用Adam之类的自适应优化器,得到的结果很有可能会离SGD的baseline差好几个点。主要原因是,自适应优化器容易找到sharp minima,泛化表现常常比SGD差得显著。
如果你训练Transformer一类的模型,Adam优化得更快且更好。主要原因是,NLP任务的loss landscape有很多“悬崖峭壁”,自适应学习率更能处理这种极端情况,避免梯度爆炸。基于同样的原因,计算机视觉很少用的gradient clipping在NLP任务里几乎必不可少。
也有一些例外。虽然生成对抗网络(GAN)一般是视觉任务,但是Adam还是成为了最流行的优化器。主要原因还是在于GAN的训练是不太稳定的,它的loss landscape和正常的视觉任务很不同。大家对训练GAN的追求是能稳定就好了,flat minima对GAN的意义还不是很明确。
对于一些不常见、归类不明确的任务,我的建议是优先使用SGD作为baseline 。Adam是一个比较heuristic,理论机制也很不清晰的方法。使用这种方法,你最好有足够的理由说服自己和别人。
问题二,比如Adam可以动态调整学习率,装进lr_scheduler不会有冲突吗?它们是如何共同工作的?
回答二:太多人有这个困惑了。我甚至遇到一些工作几年的工程师、一些PhD对这个问题也有很深的误解。答案是,自适应优化器和需要不需要LR scheduler几乎是的没有关系的,他们经常需要同时(叠加)工作。自适应优化器虽然用了自适应学习率,但是其实对学习率的选择还是非常敏感。
SGD和Adam的收敛性证明也都是要求learning rate最后会降到足够低的。但自适应优化器的学习率不会在训练中自动降到很低。
实际上你随便用CIFAR或者ImageNet跑一跑常见的模型就知道:训练的最后阶段,如果不主动把learning rate降下去,loss根本就不会自己收敛到一个比较小的值。你需要learning rate decay,从理论到实践上都太需要了。
绝大多少任务(包括计算机视觉、自然语言处理的benchmark任务):SGD需要lr scheduler,Adam也需要。
极少部分任务(训练很容易收敛或者不求完美的收敛也可以的任务):SGD不需要lr scheduler,Adam也不需要。一些MNIST的实验太简单了,一下就收敛了,就不必lr sheduler了。目前还比较流行的实验里,应该只有GAN属于这类。GAN的部分文章会用比较小的、固定的学习率的Adam,也有部分文章会用Inverse Square Root Scheduler + Adam。
问题三,哪一种lr_scheduler在大的模型上性能好?亦或是不同的模型情况会不一样?
回答三,很简单,如果你不是专门研究lr scheduler的,那么就用你的领域的顶会paper里流行的lr scheduler就行了。
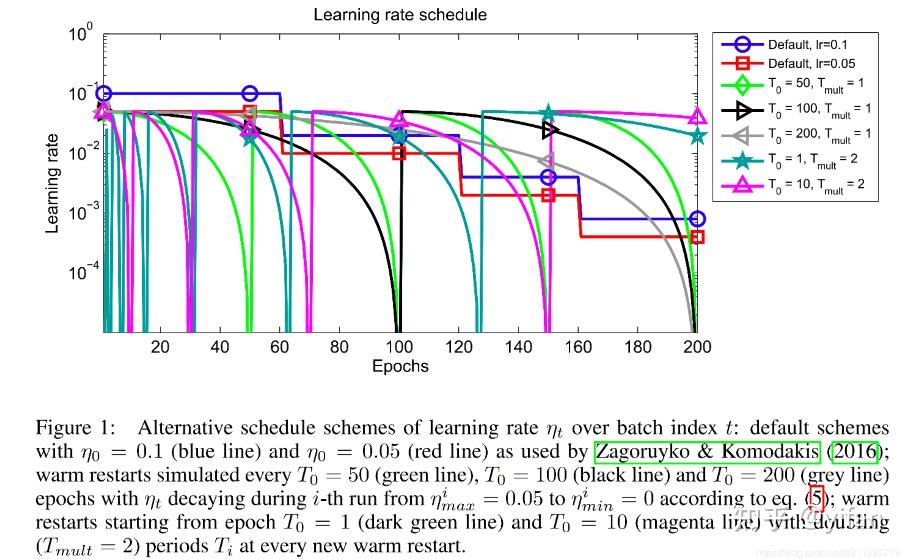
计算机视觉里一般是:(1)piecewise-constant scheduler (2)cosine annealing + warm restarts (SGDR论文宣称这是更好的选择,但是很多人觉得存疑也不太用。。)
LSTM一般是: (1)piecewise-constant scheduler (2)Inverse Square Root Scheduler
Transformer-based models一般是:(1)NOAM (为Transformer而生)
(初始学习率比较大的时候,为了防止梯度爆炸,需要在最初的几个epoch用上warmup。)
前面的大佬们回答的已经很充分了,我来补充一小点关于初始学习率的,可能有些偏题。
学习率一般也需要随着训练数据量的增大而适当降低。
理解起来也比较直观,目前大部分优化器学习到后期都会不可避免的陷入钝化阶段,这是为了避免学习后期loss剧烈抖动远离最优点。如果数据量很大,学习率不做相应调整就很容易提前进入钝化区,导致后面的数据对参数优化的贡献很低。
相应的,做领域迁移或者在线学习的时候一般要对优化器做出必要调整,简单的方法就有清空优化器中的矩估计缓存并调大学习率。
各位朋友大家好,欢迎来到月来客栈,我是掌柜空字符。
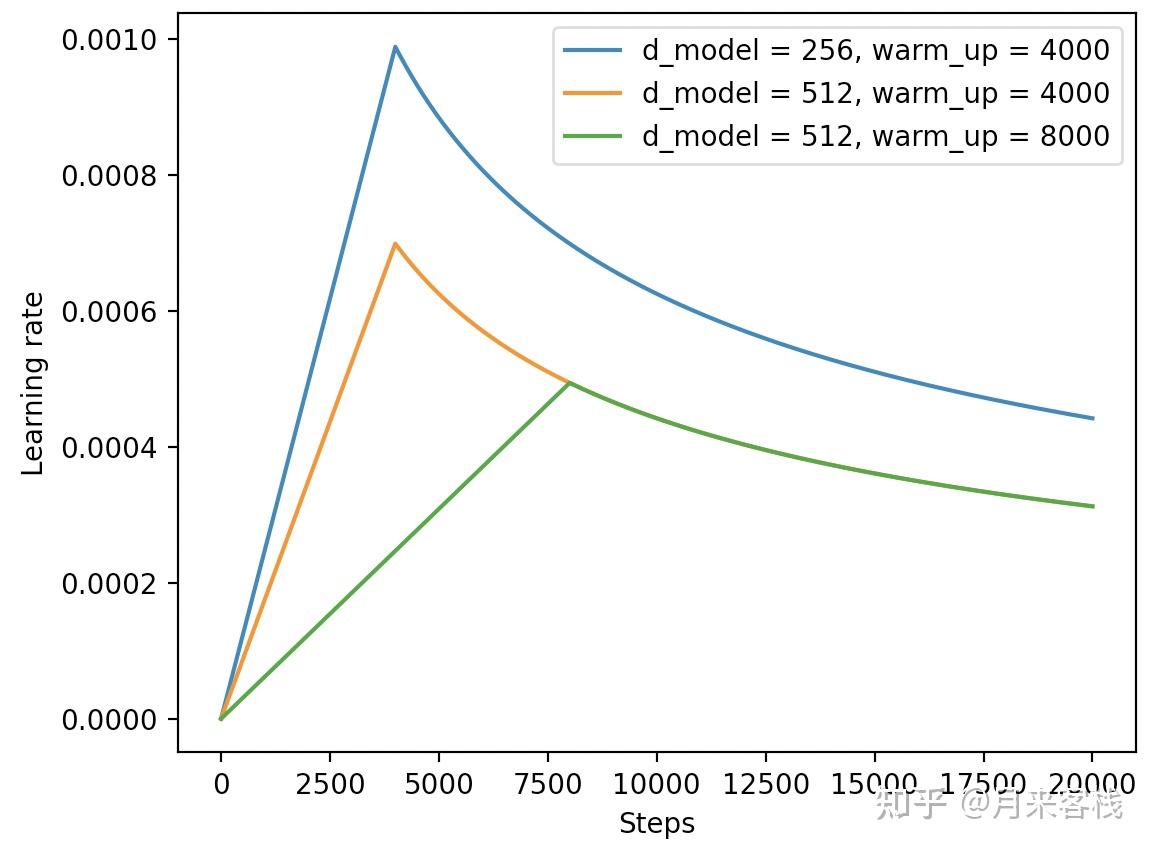
在深度学习模型的训练过程中,当训练出来的模型不那么尽如人意的时候相信大家第一时间想到的策略就是动态调整学习率。或者是在模型搭建的时候就想好了后面要通过动态调整学习率来训练模型。例如在Transformer论文中,作者就采用了如下公式来动态调整学习率:
根据公式的计算方式,模型在训练过程中学习率的变化便类似图1所示:
并且,我们还可以通过如下代码来实现模型学习率在训练过程中的动态调整:
1 class CustomSchedule(object):
2 def __init__(self, d_model, warmup_steps=4000, optimizer=None):
3 super(CustomSchedule, self).__init__()
4 self.d_model = torch.tensor(d_model, dtype=torch.float32)
5 self.warmup_steps = warmup_steps
6 self.steps = 1.
7 self.optimizer = optimizer
8
9 def step(self):
10 arg1 = self.steps ** -0.5
11 arg2 = self.steps * (self.warmup_steps ** -1.5)
12 self.steps += 1.
13 lr = (self.d_model ** -0.5) * min(arg1, arg2)
14 for p in self.optimizer.param_groups:
15 p['lr'] = lr
16 return lr
17
18 def train(config):
19 optimizer = torch.optim.Adam(translation_model.parameters(),
20 lr=0.,
21 betas=(config.beta1, config.beta2), eps=config.epsilon)
22 lr_scheduler = CustomSchedule(config.d_model, optimizer=optimizer)
23 ...
24 loss.backward()
25 lr_scheduler.step()
26 optimizer.step()
27 ...在上述代码中,第1-16行是整个自定义学习率的实现部分,其中warmup_steps表示学习率在达到最大值前的一个“热身步数”(例如图1中的直线部分);第25行则是在每个训练的step中对学习率进行更新;第26行则是采用更新后的学习率对模型参数进行更新。
当然,对于这类复杂或并不常见的学习率动态调整确实需要我们自己来编码实现,但是对于一些常见的常数、线性、余弦变换等学习率调整,我们可以直接借助Transformers框架中的optimization模块来实现。
在本篇文章中,掌柜将会先来介绍如何直接使用Transformers框架中的optimization模块来快速实现学习率动态调整的目的;然后再来简单介绍一下各个方法背后的实现逻辑以及如何模仿来实现自定义的方法。
在Transformers框架中,我们可以通过如下方式来导入optimization模块:
1 from transformers import optimization在optimization模块中,一共包含了6种常见的学习率动态调整方式,包括constant、constant_with_warmup、linear、polynomial、cosine 和cosine_with_restarts,其分别通过一个函数来返回对应的实例化对象。
下面掌柜就开始依次对这6种动态学习率调整方式进行介绍。
在optimization模块中可以通过get_constant_schedule函数来返回对应的常数动态学习率调整方法。顾名思义,常数学习率动态调整就是学习率是一个恒定不变的常数,也就是说相当于没用。为了方便后续对学习率的变化进行可视化,这里我们先随便定义一个网络模型,如下:
1 import torch
2 import torch.nn as nn
3
4 class Model(nn.Module):
5 def __init__(self):
6 super(Model, self).__init__()
7 self.fc = nn.Linear(5, 10)
8
9 def forward(self, x):
10 out = self.fc(x).sum()
11 return out进一步,在模型训练的过程中,我们可以通过以下方式来进行使用:
1 from transformers import optimization
2
3 if __name__ == '__main__':
4 x = torch.rand([8, 5])
5 model = Model()
6 model.train()
7 steps = 1000
8 optimizer = torch.optim.Adam(model.parameters(), lr=1.0)
9 scheduler = optimization.get_constant_schedule(optimizer, last_epoch=-1)
10 lrs = []
11 for _ in range(steps):
12 loss = model(x)
13 optimizer.zero_grad()
14 loss.backward()
15 optimizer.step()
16 scheduler.step()
17 lrs.append(scheduler.get_last_lr()) 在上述代码中,第9行便是用来得到对应的常数学习率变化的实例化对象,其中last_epoch用于在恢复训练时指定上次结束时的epoch数量,因为有些方法学习率的变化会与epoch数有关,如果不考虑模型恢复的话指定为-1即可,这部分内容掌柜将在本文最后进行详细介绍;第16行则是对学习率进行更新;第17行则是取出对应的学习率便于可视化。
在模型训练结束后(或者采用tensorboard)便可以对学习率的变化进行可视化了,代码如下:
1 plt.figure(figsize=(7, 4))
2 plt.plot(range(steps), lrs, label=name)
3 plt.legend(fontsize=13)
4 plt.show()上述方法的可视化结果如下:
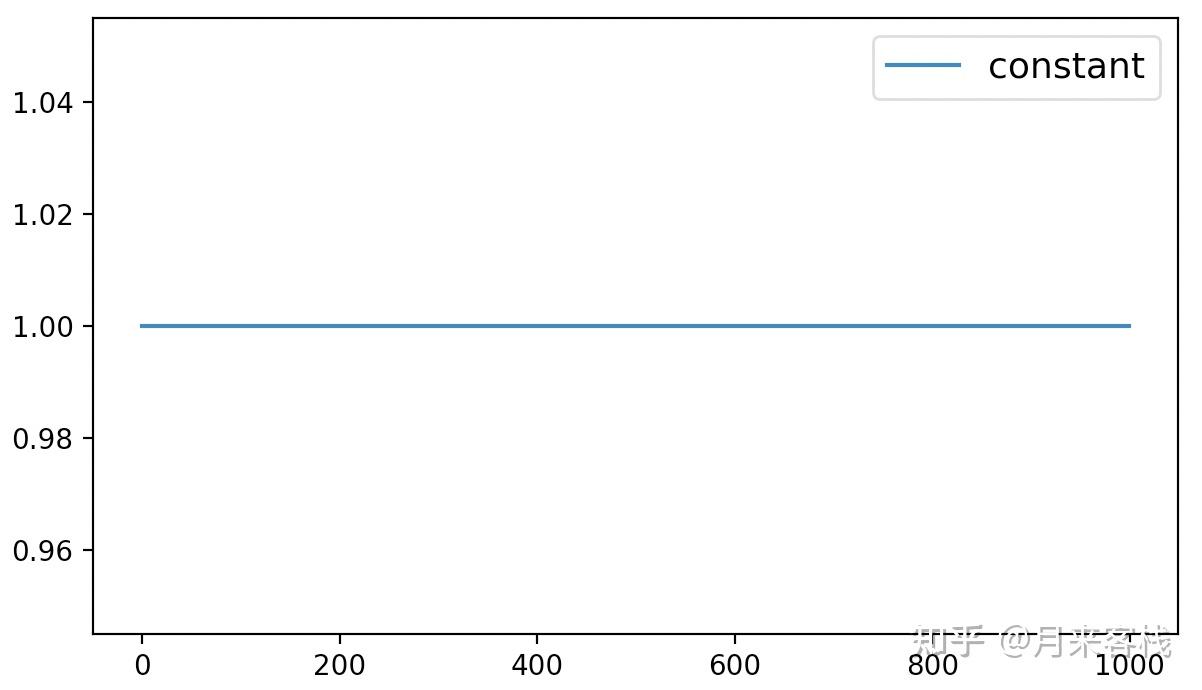
如图2所示,模型在整个训练过程中的学习率并没有发生变化,都是保持着1.0的初始值。
在optimization模块中可以通过get_constant_schedule_with_warmup函数来返回对应的动态学习率调整的实例化方法。从名字可以看出,该方法最终得到的是一个带warmup的常数学习率变化。在模型训练的过程中,我们可以通过以下方式来进行使用:
1 scheduler = optimization.get_constant_schedule_with_warmup(optimizer, num_warmup_steps=300)其中num_warmup_steps表示warmpup的数量。
最后,该方法的可视化结果如下所示:
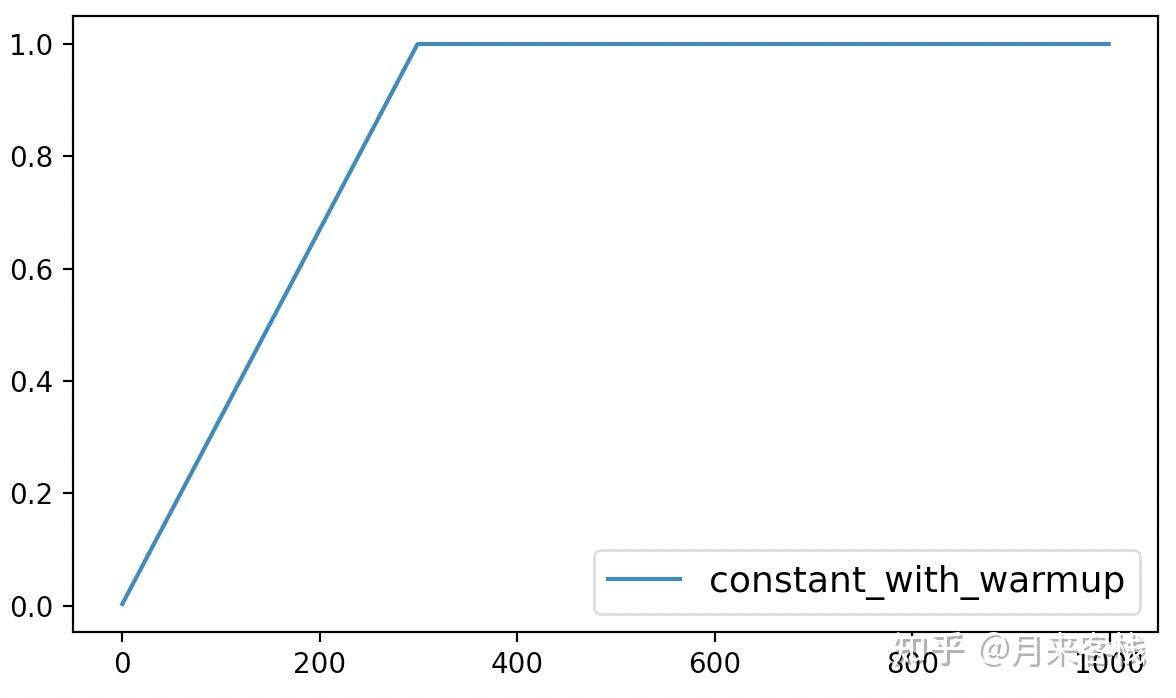
从图3可以看出constant_with_warmup仅仅只是在最初的300个steps中以线性的方式进行增长,之后便是同样保持为常数。
在optimization模块中可以通过get_constant_schedule_with_warmup函数来返回对应的动态学习率调整的实例化方法。从名字可以看出,该方法最终得到的是一个带warmup的常数学习率变化。在模型训练的过程中,我们可以通过以下方式来进行使用:
1 scheduler = optimization.get_linear_schedule_with_warmup(optimizer,
2 num_warmup_steps=300,
3 num_training_steps=steps)其中num_training_steps表示整个模型训练的step数。
最后,该方法的可视化结果如下所示:
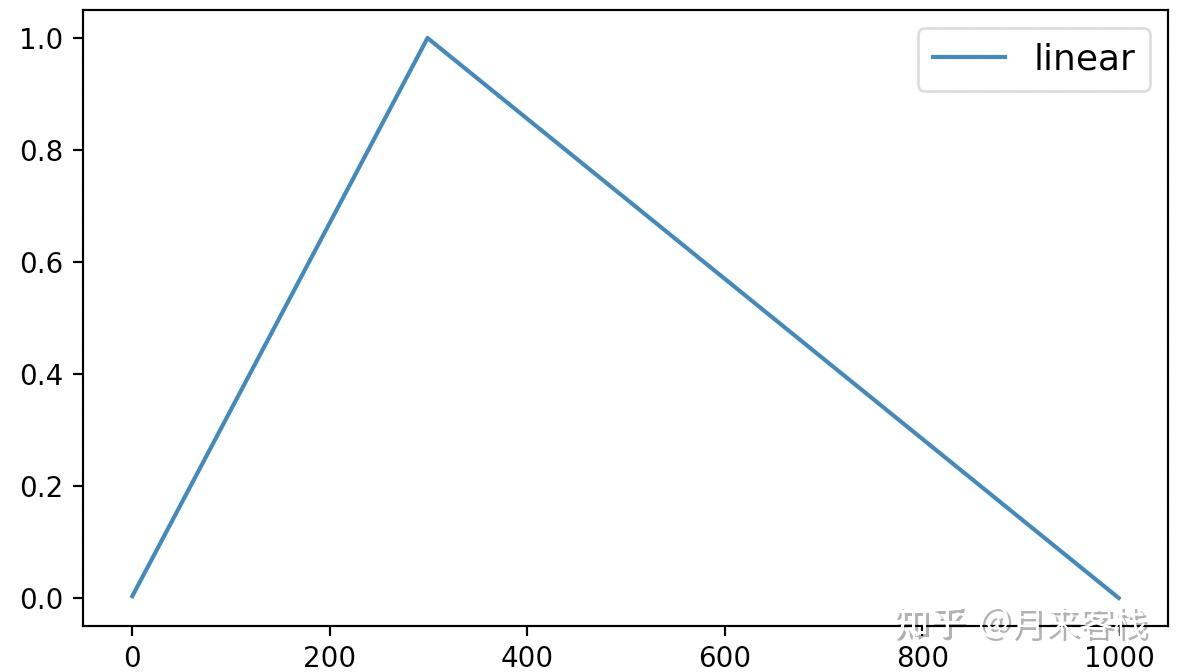
从图4可以看出linear动态学习率调整先是在最初的300个steps中以线性的方式进行增长,之后便是同样以线性的方式进行递减,直到衰减到0为止。
在optimization模块中可以通过get_constant_schedule_with_warmup函数来返回对应的动态学习率调整的实例化方法。从名字可以看出,该方法最终得到的是一个基于多项式的学习率动态调整策略。在模型训练的过程中,我们可以通过以下方式来进行使用:
1 scheduler = optimization.get_polynomial_decay_schedule_with_warmup(optimizer,
2 num_warmup_steps=300,
3 num_training_steps=steps,
4 lr_end = 1e-7,
5 power=3)其中power表示多项式的次数,当power=1时(默认)等价于get_linear_schedule_with_warmup函数;lr_end表示学习率衰减到的最小值。
最后,该方法的可视化结果如下所示:
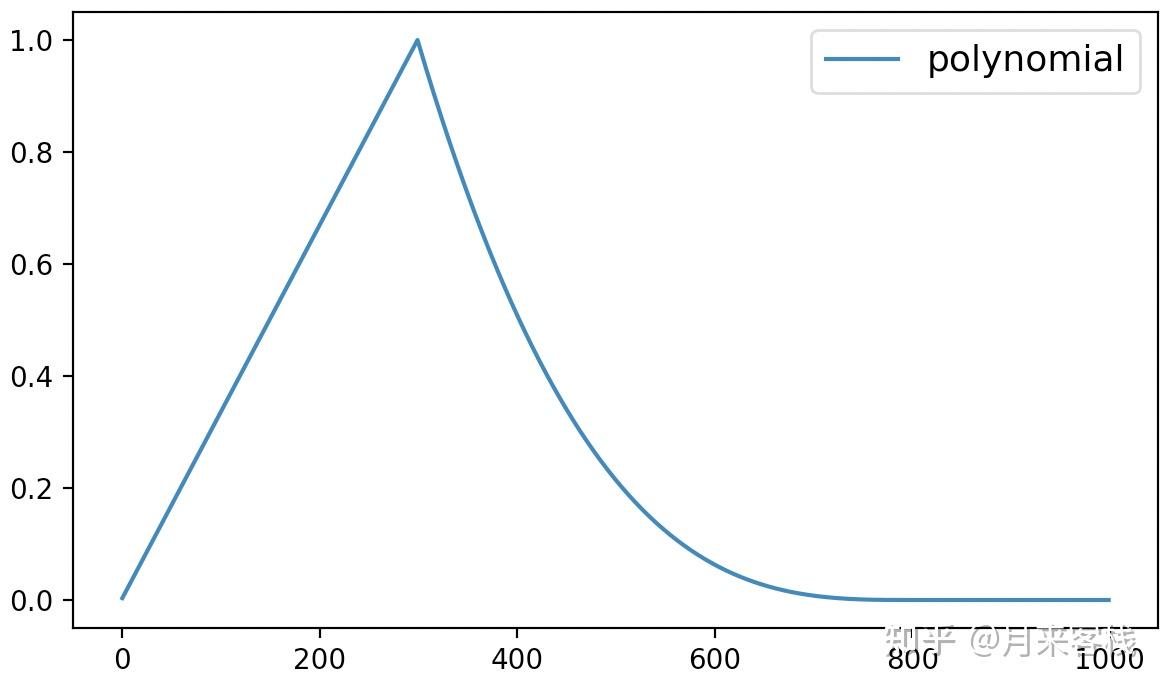
从图5可以看出polynomial动态学习率调整先是在最初的300个steps中以线性的方式进行增长,之后便是多项式的方式进行递减,直到衰减到lr_end后保持不变。
在optimization模块中可以通过get_cosine_schedule_with_warmup来返回基于cosine函数的动态学习率调整方法。在模型训练过程中我们可以通过如下方式来进行调用:
1 scheduler = optimization.get_cosine_schedule_with_warmup(optimizer,
2 num_warmup_steps=300,
3 num_training_steps=steps,
4 num_cycles=2)其中num_cycles表示循环的次数。
最后,该方法的可视化结果如下所示:
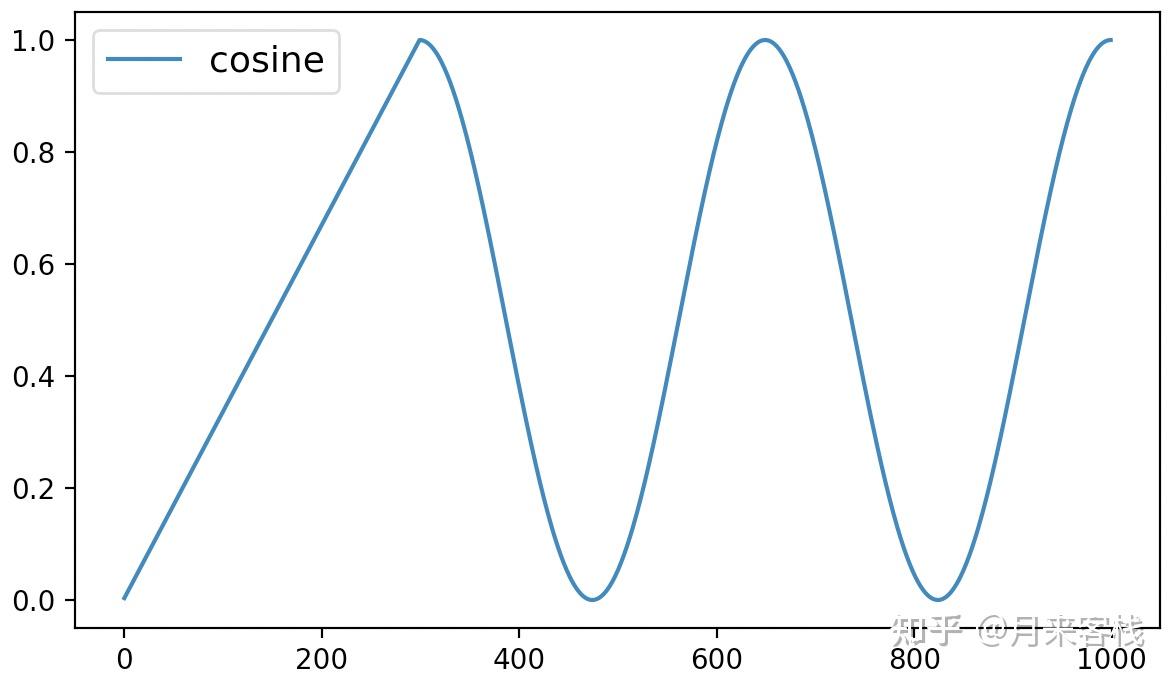
从图6可以看出cosine动态学习率调整方法先是在最初的300个steps中以线性的方式进行增长,之后便是以余弦函数的方式进行周期性变换。
在optimization模块中可以通过get_cosine_with_hard_restarts_schedule_with_warmup来返回基于cosine函数的硬重启动态学习率调整方法。所谓硬重启就是学习率衰减到0之后直接变回到最大值的方式。在模型训练过程中我们可以通过如下方式来进行调用:
1 scheduler = optimization.get_cosine_with_hard_restarts_schedule_with_warmup(optimizer,
2 num_warmup_steps=300,
3 num_training_steps=steps,
4 num_cycles=2)最后,该方法的可视化结果如下所示:
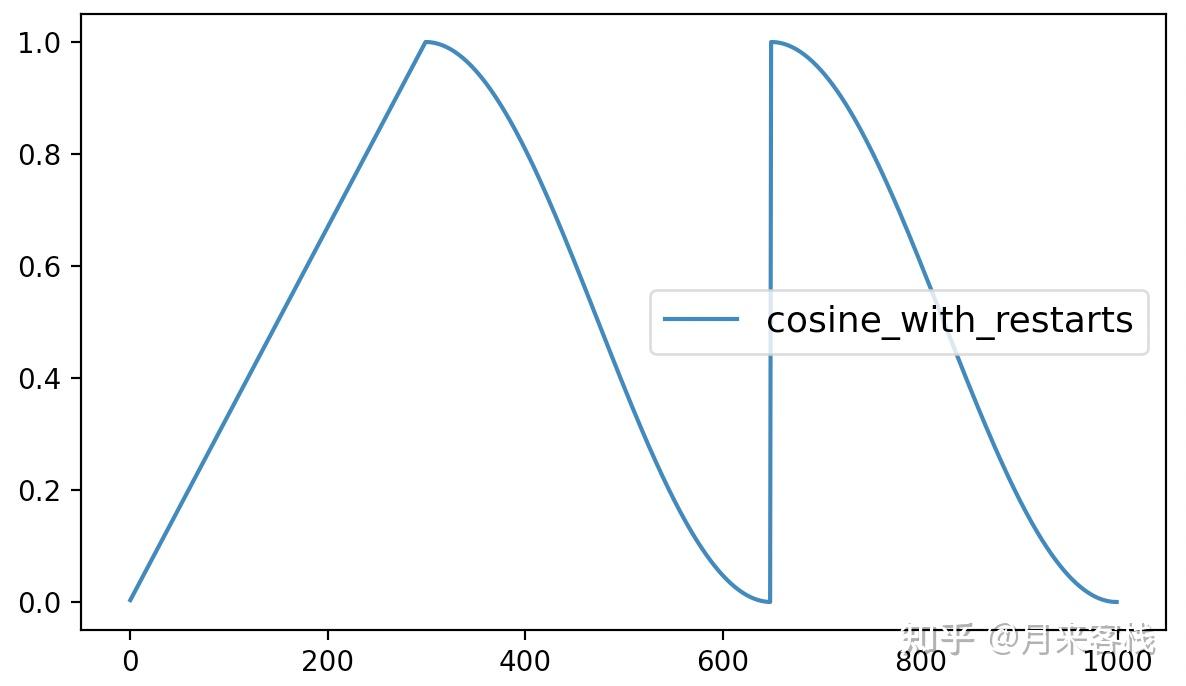
从图7可以看出cosine_with_restarts动态学习率调整方法先是在最初的300个steps中以线性的方式进行增长,之后便是以余弦函数的方式进行周期性衰减,当达到最小值时再直接恢复到初始学习率。
通过上述6个函数,我们便能够返回得到相应的动态学习率调整方法。当然,如果你并不需要修改一些特定的参数,例如多项式中的power和余弦变换中的num_cycles等,那么你还可以使用一个更加简单的统一接口来调用上述6个方法:
1 from transformers import get_scheduler
2 def get_scheduler(
3 name: Union[str, SchedulerType],
4 optimizer: Optimizer,
5 num_warmup_steps: Optional[int] = None,
6 num_training_steps: Optional[int] = None):在上述代码中,第3行name表示指定学习率调整的方式,可选项就是上面介绍的6种,并且通过constant、constant_with_warmup、linear、polynomial、cosine 和cosine_with_restarts这6个关键字就能够返回得到对应的方法;而对于其它特定的参数则会保持每个方法对应的默认值。例如通过get_scheduler函数返回get_cosine_with_hard_restarts_schedule_with_warmup时,num_cycles则为1
例如:
1 scheduler = optimization.get_cosine_with_hard_restarts_schedule_with_warmup(optimizer,
2 num_warmup_steps=300,
3 num_training_steps=steps,
4 num_cycles=1)
5 scheduler = get_scheduler(name="cosine_with_restarts", optimizer=optimizer,
6 num_warmup_steps=300, num_training_steps=steps)在上述代码中,两种方式返回得到的学习调整方式都是一样的;但是如果想要返回num_cycles=2的情况那就不能通过get_scheduler函数获得。
到此,对于Transformes框架中常见的6中学习率动态调整方法及使用示例就介绍完了。
对于Transformers框架中实现的这6种学习率动态调整方法本质上也是基于PyTorch框架中的LambdaLR类而来。
1 from torch.optim.lr_scheduler import LambdaLR
2 class LambdaLR(_LRScheduler):
3 def __init__(self, optimizer, lr_lambda, last_epoch=-1):
4 pass通过这个接口,我们只需要指定优化器、学习率系数的计算方式(函数)以及last_epoch参数来实例化类LambdaLR便可以返回得到相应的实例化对象。下面掌柜就来依次进行一个简单的介绍。
对于constant的计算过程来说比较简答, 只需要传入一个返回值始终为1.0的匿名函数即可。因为返回的1将会作为一个系数乘以我们初始设定的学习率。实现代码如下:
def get_constant_schedule(Optimizer, last_epoch=-1):
return LambdaLR(optimizer, lambda _: 1, last_epoch=last_epoch)在上述代码中,lambda _:1就是对应返回值为1的匿名函数。
对于constant_with_warmup的计算过程来说同样也比较简单。整体逻辑便是在num_warmup_steps之前系数保持线性增长,在num_warmup_steps之后保持为1.0不变即可,即:
根据公式,最终实现代码如下所示:
1 def get_constant_schedule_with_warmup(Optimizer, num_warmup_steps,last_epoch = -1):
2 def lr_lambda(current_step):
3 if current_step < num_warmup_steps:
4 return float(current_step) / float(max(1.0, num_warmup_steps))
5 return 1.0
6 return LambdaLR(optimizer, lr_lambda, last_epoch=last_epoch)这里掌柜需要再次提醒大家的是,lr_lambda()返回的是学习率的变换系数,该系数乘以初始的学习率才是最终模型用到的学习率。例如上述代码中当current_step大于等于num_warmup_steps时返回的系数就是1,这样就能保证在这之后学习率就会保持初始设定的学习率不变。
对于linear的系数计算过程来说只需要分别在num_warmup_steps之前和之后分别保持线性增加和线性减少即可,即:
根据公式,最终实现代码如下所示:
1 def get_linear_schedule_with_warmup(optimizer, num_warmup_steps, num_training_steps, last_epoch=-1):
2 def lr_lambda(current_step: int):
3 if current_step < num_warmup_steps:
4 return float(current_step) / float(max(1, num_warmup_steps))
5 return max( 0.0, float(num_training_steps - current_step) /
6 float(max(1, num_training_steps - num_warmup_steps)))
7 return LambdaLR(optimizer, lr_lambda, last_epoch)对于polynomial的系数计算过程来说则稍微复杂了一点,其整体逻辑便是在num_warmup_steps之前系数保持线性增长,在num_warmup_steps之后保持为定值不变,在两者之间则以对应的多项式函数进行变换,计算公式式如下:
其中表示初始设定的学习率。
根据公式,最终实现代码如下所示:
1 def get_polynomial_decay_schedule_with_warmup(optimizer,
2 num_warmup_steps, num_training_steps, lr_end=1e-7, power=1.0, last_epoch=-1):
3 lr_init = optimizer.defaults["lr"]
4 assert lr_init > lr_end, f"lr_end ({lr_end}) must be be smaller than initial lr ({lr_init})"
5 def lr_lambda(current_step):
6 if current_step < num_warmup_steps:
7 return float(current_step) / float(max(1, num_warmup_steps))
8 elif current_step > num_training_steps:
9 return lr_end / lr_init # as LambdaLR multiplies by lr_init
10 else:
11 lr_range = lr_init - lr_end
12 decay_steps = num_training_steps - num_warmup_steps
13 pct_remaining = 1 - (current_step - num_warmup_steps) / decay_steps
14 decay = lr_range * pct_remaining ** power + lr_end
15 return decay / lr_init # as LambdaLR multiplies by lr_init
16 return LambdaLR(optimizer, lr_lambda, last_epoch)对于cosine学习率动态变换的系数计算过程来说就稍微更复杂了,其整体逻辑便是在num_warmup_steps之前系数保持线性增长,在num_warmup_steps之后则以对应的余弦函数进行变换,计算公式如下:
根据公式,最终实现代码如下所示:
1 def get_cosine_schedule_with_warmup(optimizer, num_warmup_steps,
2 num_training_steps, num_cycles = 0.5, last_epoch = -1):
3 def lr_lambda(current_step):
4 if current_step < num_warmup_steps:
5 return float(current_step) / float(max(1, num_warmup_steps))
6 progress = float(current_step - num_warmup_steps) /
7 float(max(1, num_training_steps - num_warmup_steps))
8 return max(0.0, 0.5 * (1.0 + math.cos(math.pi * float(num_cycles) * 2.0 * progress)))
9 return LambdaLR(optimizer, lr_lambda, last_epoch)对于cosine_with_restarts学习率动态变换的系数计算过程来说,总体上与cosine方式的实现过程类似,仅仅只是多增加了一个条件判断,具体计算公式如下:
其中表示取余。
根据公式,最终实现代码如下所示:
1 def get_cosine_with_hard_restarts_schedule_with_warmup(optimizer, num_warmup_steps,
2 num_training_steps, num_cycles = 1, last_epoch = -1):
3 def lr_lambda(current_step):
4 if current_step < num_warmup_steps:
5 return float(current_step) / float(max(1, num_warmup_steps))
6 progress = float(current_step - num_warmup_steps) /
7 float(max(1, num_training_steps - num_warmup_steps))
8 if progress >= 1.0:
9 return 0.0
10 return max(0.0, 0.5 * (1.0 + math.cos(math.pi * ((float(num_cycles) * progress) % 1.0))))
11 return LambdaLR(optimizer, lr_lambda, last_epoch)经过上述几种动态学习率调整方法实现的介绍,对于公式也就是Transformer论文中学习率的调整,我们也可以模仿上述的方式来进行实现:
1 def get_customized_schedule_with_warmup(optimizer, num_warmup_steps, d_model=1.0, last_epoch=-1):
2 def lr_lambda(current_step):
3 current_step += 1
4 arg1 = current_step ** -0.5
5 arg2 = current_step * (num_warmup_steps ** -1.5)
6 return (d_model ** -0.5) * min(arg1, arg2)
7
8 return LambdaLR(optimizer, lr_lambda, last_epoch)由于公式计算学习率的方法并不涉及到初始学习率的,所以在后面初始化
Adam()时参数lr需要赋值为1.0,这样get_customized_schedule_with_warmup返回后的结果就直接是我们需要的学习率了。当然,也可以直接在上述代码第6行的返回值中再加上除以初始学习率,这样后续就不用有学习率必须设置为1的限制了,各位客官理解便是。
进一步我们就可以通过上述类似方式来使用该方法:
1 optimizer = torch.optim.Adam(model.parameters(), lr=1.0)
2 scheduler = get_customized_schedule_with_warmup(optimizer,
3 num_warmup_steps=200,
4 d_model=728)最终同样会得到如下图所示的学习率变化曲线:
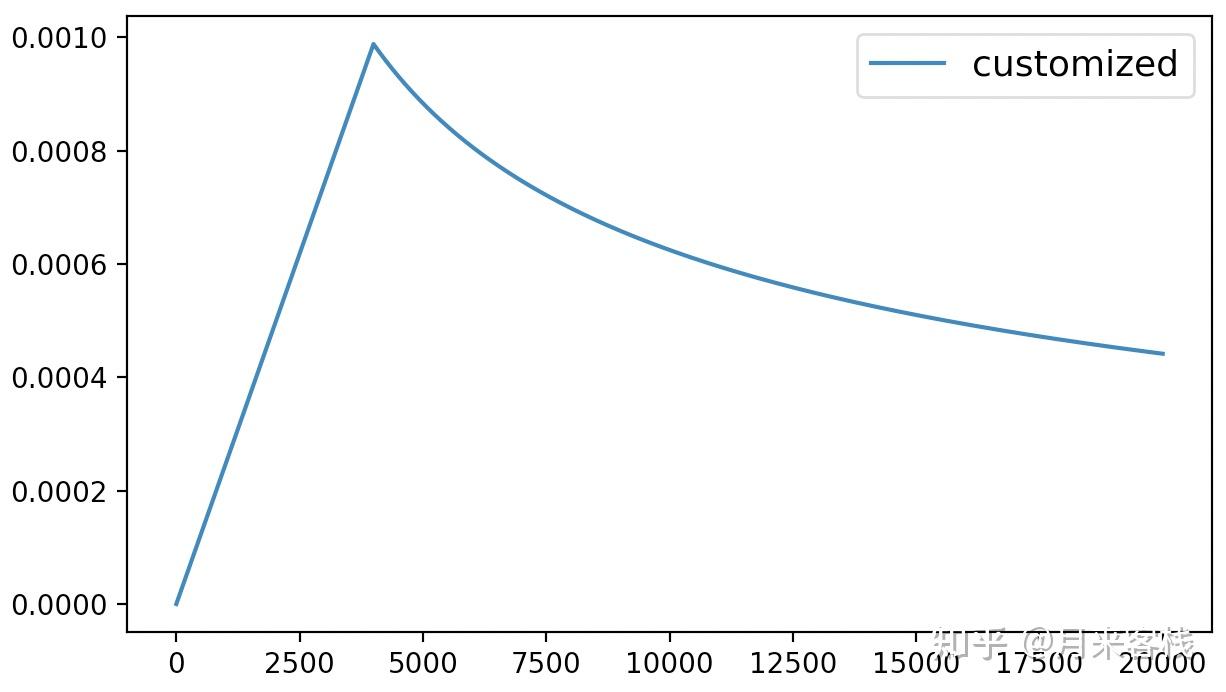
在介绍完上述几种动态学习率调整及自定义的用法后,我们再来大致看看底层LambdaLR的实现逻辑,这样更有利于我们灵活的使用上述方法。当然,如果有客官暂时只想停留在对上述6种方式的使用层面,那么后续内容可以先行略过,等有需要再来查阅。
翻阅LambdaLR类的实现代码可以发现,类LambdaLR是继承自类_LRScheduler,两者之中各类的类方法和类成员变量如下:
1 class _LRScheduler(object):
2
3 def __init__(self, optimizer, last_epoch=-1):
4 if last_epoch == -1:
5 for group in optimizer.param_groups:
6 group.setdefault('initial_lr', group['lr'])
7 ......
8 self.base_lrs = list(map(lambda group: group['initial_lr'], optimizer.param_groups))
9 self.last_epoch = last_epoch
10 ......
11 self.step()
12
13 def get_lr(self):
14 raise NotImplementedError
15
16 def step(self, epoch=None):
17 ......
18 self._step_count += 1
19 with _enable_get_lr_call(self):
20 if epoch is None:
21 self.last_epoch += 1
22 values = self.get_lr()
23 else:
24 self.last_epoch = epoch
25 if hasattr(self, "_get_closed_form_lr"):
26 values = self._get_closed_form_lr()
27 else:
28 values = self.get_lr()
29 for param_group, lr in zip(self.optimizer.param_groups, values):
30 param_group['lr'] = lr
31 ......
32
33 class LambdaLR(_LRScheduler):
34
35 def __init__(self, optimizer, lr_lambda, last_epoch=-1):
36 self.optimizer = optimizer
37 self.last_epoch = last_epoch
38 super(LambdaLR, self).__init__(optimizer, last_epoch)
39
40 def get_lr(self):
41 return [base_lr * lmbda(self.last_epoch)
42 for lmbda, base_lr in zip(self.lr_lambdas, self.base_lrs)]注意: 上述代码并非完整部分,掌柜只是对其中的关键部分进行摘取。
要理解整个动态学习率的计算过程最重要的就是弄清楚get_lr()和step()这两个方法。从第3节中的使用示例可以发现,模型在训练过程中是通过step()这个方法来实现学习率更新的,因此这里我们就从step()方法入手来进行研究。
从上述代码第16行可以发现,其实step()方法在调用时还会接受一个epoch参数,但我们在前面的使用过程中并没有传入,那它又有什么用呢?进一步,从第20-22行可以当epoch为None时,那么self.last_epoch就会累计加1;而如果epoch不为None那么self.last_epoch就会直接取epoch的值;接着便是通过self.get_lr()函数来获取当前的学习率。在得到当前学习率的计算结果后,再通过第29-30行代码将其传入到优化器中便实现了学习率的动态调整。
接着我们再来看LambdaLR中get_lr()部分的实现代码。从第40-42行代码可知,self.lr_lambdas就是LambdaLR实例化时传入的参数lr_lambda,也就是第3节中介绍的学习率系数的计算函数;而self.last_epoch就是前面对应的current_step参数。从这里我们就可以发现,LambdaLR中epoch这个概念不仅仅有我们平常训练时所说的迭代“轮”数,也可以理解成训练时参数更新的次数。
从第20-28行的逻辑可以看出,如果在使用过程中需要学习率在每个batch参数更新时都发生变化,那么最简单的做法就是调用step()方法时不指定epoch;如果仅仅是需要在每个epoch(轮)后学习率才发生变化,那么在调用step()方法时指定epoch为当前的轮数即可,例如:
1 for epoch in epoches:
2 for data in data_iter:
3 optimizer.step()
4 scheduler.step(epoch=epoch)通常来说,前一种方式(在每batch参数更新后学习率都发生改变)用到的时候更多,也就是第3节总介绍到的示例。
同时,根据上述代码第3-8行可知,当last_epoch=-1时,_LRScheduler就默认当前为模型刚开始训练时的状态,并把optimizer中的lr参数作为初始学习率initial_lr,也就是后续的self.base_lrs,就被用于在第42行中计算当前的学习率。当last_epoch不为-1时,也就意味着此时是的模型可能是需要恢复到之前的某个时刻继续进行训练,那么学习率也就需要恢复到之前结束的那一刻。
到此,对于类LambdaLR的实现逻辑就算是基本介绍完了。下面掌柜再来介绍最后一个示例,即如何通过指定last_epoch来恢复到学习率之前的状态继续进行追加训练。
假如某位客官正在采用cosine方法作为学习率动态调整策略来训练模型,并且在训练3个epoch后便结束了训练。同时也得到了如图9所示的学习率变化曲线:
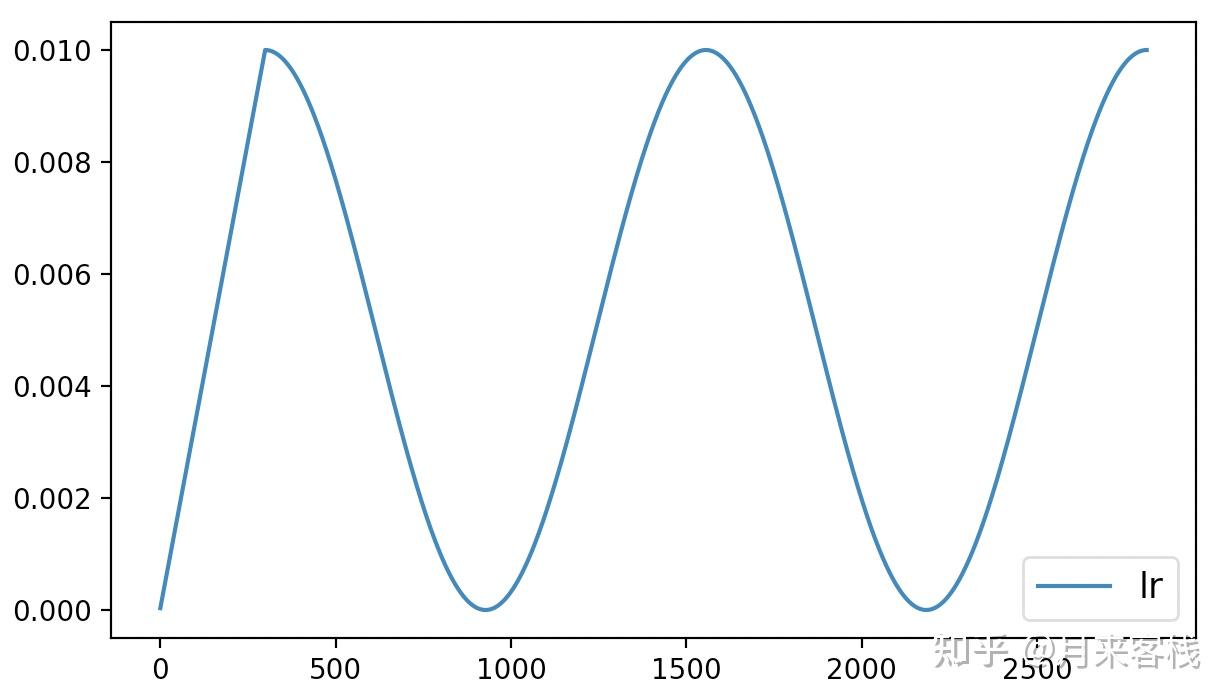
在这位客官认真分析完训练产生的相关数据后认为,模型如果继续进行训练应该还能获得更好的结果于是就打算对之前保存的模型进行追加训练。但是学习率要怎么样才能恢复到之前结束时的状态呢?也就是说模型在进行追加训练时学习率应该接着之前的状态继续进行,而不是像图9那样又从头开始。
此时,我们便可以通过如下代码来实现上述目的:
1 last_epoch = -1
2 if os.path.exists('https://www.zhihu.com/question/model.pt'):
3 checkpoint = torch.load('https://www.zhihu.com/question/model.pt')
4 last_epoch = checkpoint['last_epoch']
5 self.model.load_state_dict(checkpoint['model_state_dict'])
6
7 num_training_steps = len(train_iter) * self.epochs
8 optimizer = torch.optim.Adam([{"params": self.model.parameters(),
9 "initial_lr": self.learning_rate}])
10 scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=300,
11 num_training_steps=num_training_steps,
12 num_cycles=2, last_epoch=last_epoch)
13 for epoch in range(self.epochs):
14 for i, (x, y) in enumerate(train_iter):
15 loss, logits = self.model(x, y)
16 optimizer.zero_grad()
17 loss.backward()
18 optimizer.step() # 执行梯度下降
19 scheduler.step()
20 lrs.append(scheduler.get_last_lr())
21 ......
22 torch.save({'last_epoch': scheduler.last_epoch,
23 'model_state_dict': self.model.state_dict()},
24 'https://www.zhihu.com/question/model.pt')在上述代码中,第2-5行用来判断本地是否存在模型,如果存在则获取对应的参数值;第7-12行则分别用来定义和实例化相关方法,当本地不存在模型时last_epoch将作为-1被传递到get_cosine_schedule_with_warmup中,即此时学习率从头开始变换;第22-24行则是对训练结束后的模型参数进行保存,同时也保存了last_epoch的值。
这里需要注意一点的是,只要在优化器中指定了initial_lr参数, 那么LambdaLR在动态计算学习率时的base_lr就是initial_lr对应的值,与优化器中的指定的lr参数也就没有了关系。
当后续再对模型进行追加训练时,第4行代码便获取得到了last_epoch上一次训练结束后的值,接着后续训练时学习率就可以接着上一次结束时的状态继续进行。最终我们也可以得到如图10所示的学习率变化曲线:
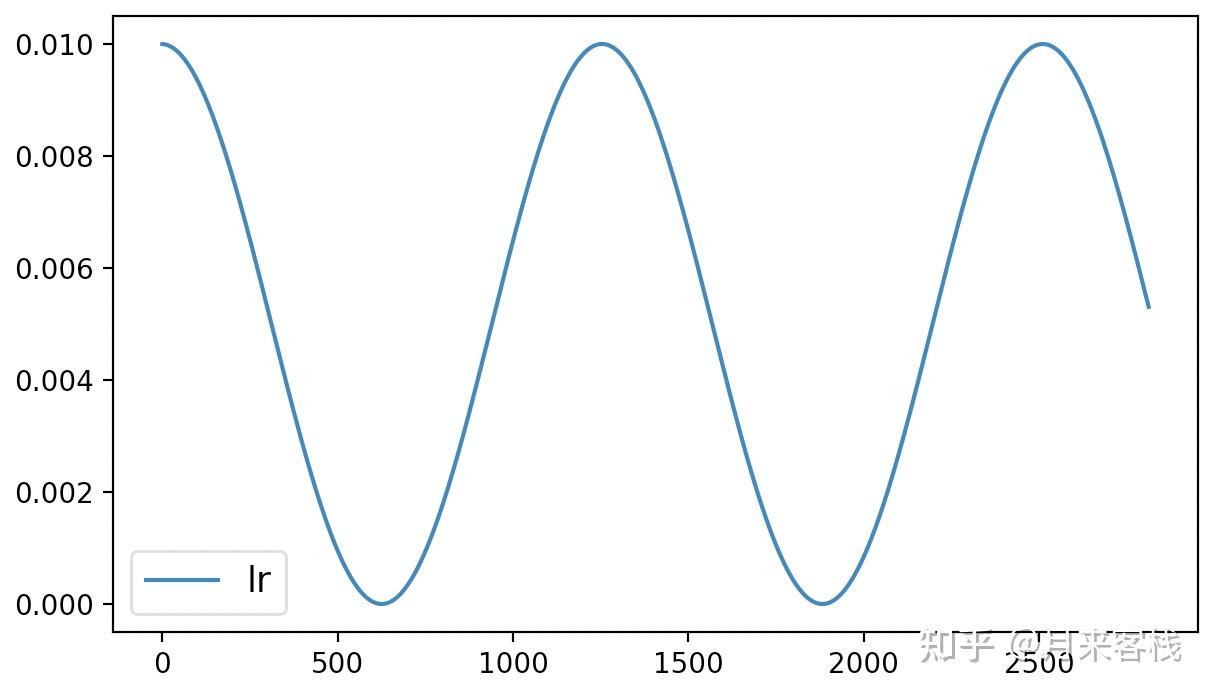
从图10可以看出,学习率的初始值就是接着图9中学习率的结束值开始进行的变换。
在本篇文章中,掌柜首先通过一个实例引出了什么是动态学习率调整;然后详细介绍了如何通过Transformers框架中的optimization模块来调用其实现的6种常见的动态学习率调整策略,并逐一进行了示例;接着介绍了PyTorch框架底层LambdaLR的实现逻辑,并对其中相关重要参数进行了讲解;最后通过一个示例介绍了如何在对模型进行追加训练时也能使得学习率恢复到之前训练时的状态。
本次内容就到此结束,感谢您的阅读!如果你觉得上述内容对你有所帮助,欢迎点赞转发分享三连!青山不改,绿水长流,我们月来客栈见!
[1]示例代码 https://github.com/moon-hotel/DeepLearningWithMe
月来客栈:如何用@修饰器来缓存数据预处理结果?月来客栈:Pytorch模型的保存与迁移月来客栈:训练模型是如何便捷保存日志?本文首发于公众号『机器学习研习院』
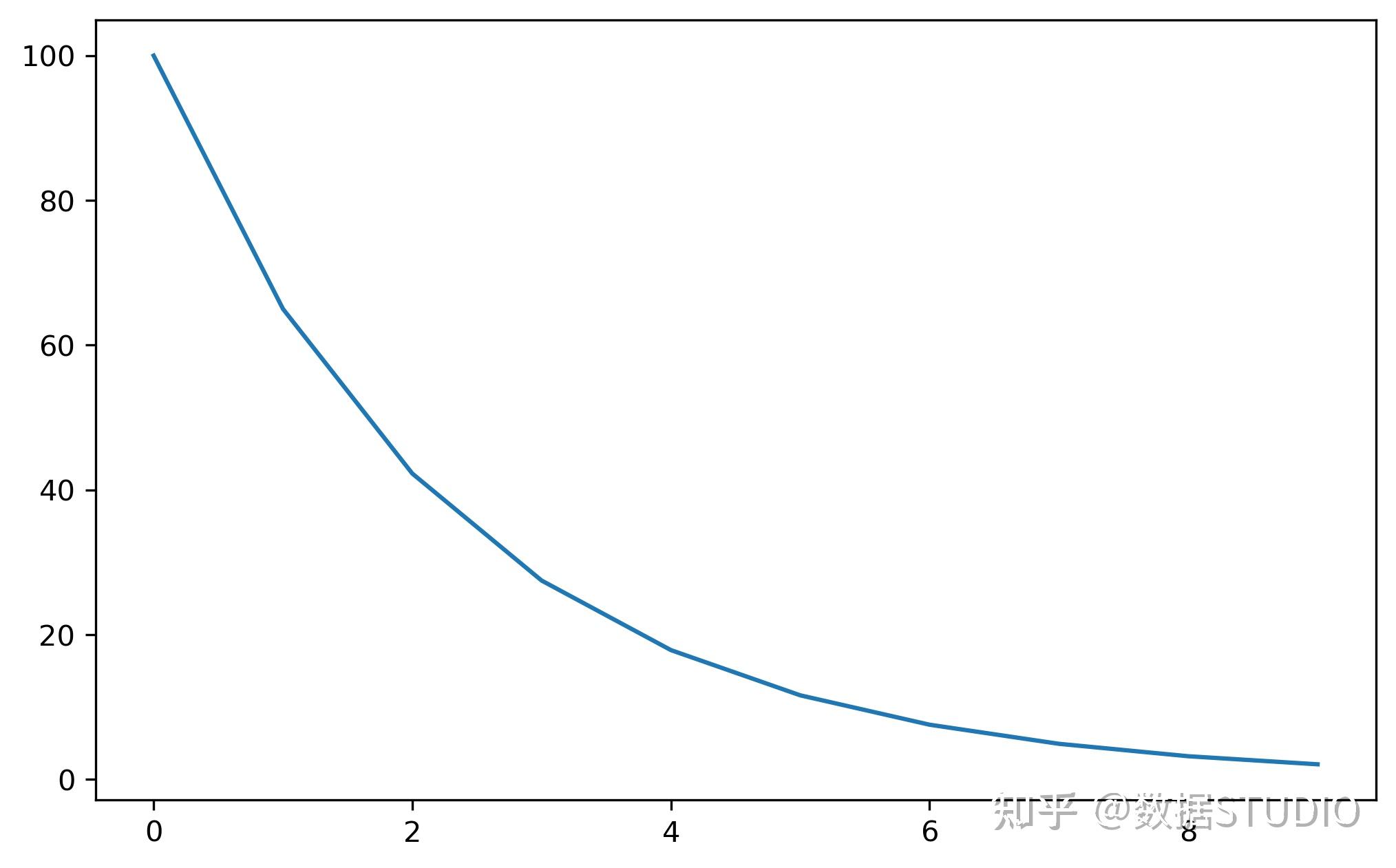
图解 9 种Torch中常用的学习率调整策略将每个参数组的学习率设置为初始lr乘以给定函数。当last_epoch=-1时,将初始lr设置为初始值。
torch.optim.lr_scheduler.LambdaLR(optimizer,
lr_lambda,
last_epoch=-1,
verbose=False,)
lr_lambda(函数或列表):一个函数,给定一个整数形参epoch计算乘法因子,或一个这样的函数列表,optimizer.param_groups中的每组一个。last_epoch(int):最后一个epoch的索引。默认值:1。verbose(bool):如果为True,则在每次更新时向标准输出输出一条消息。默认值:False。
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=100)
lambda1 = lambda epoch: 0.65 ** epoch
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda1)
lrs = []
for i in range(10):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor=", round(0.65 ** i,3)," , Learning Rate=",round(optimizer.param_groups[0]["lr"],3))
scheduler.step()
plt.plot(range(10),lrs)
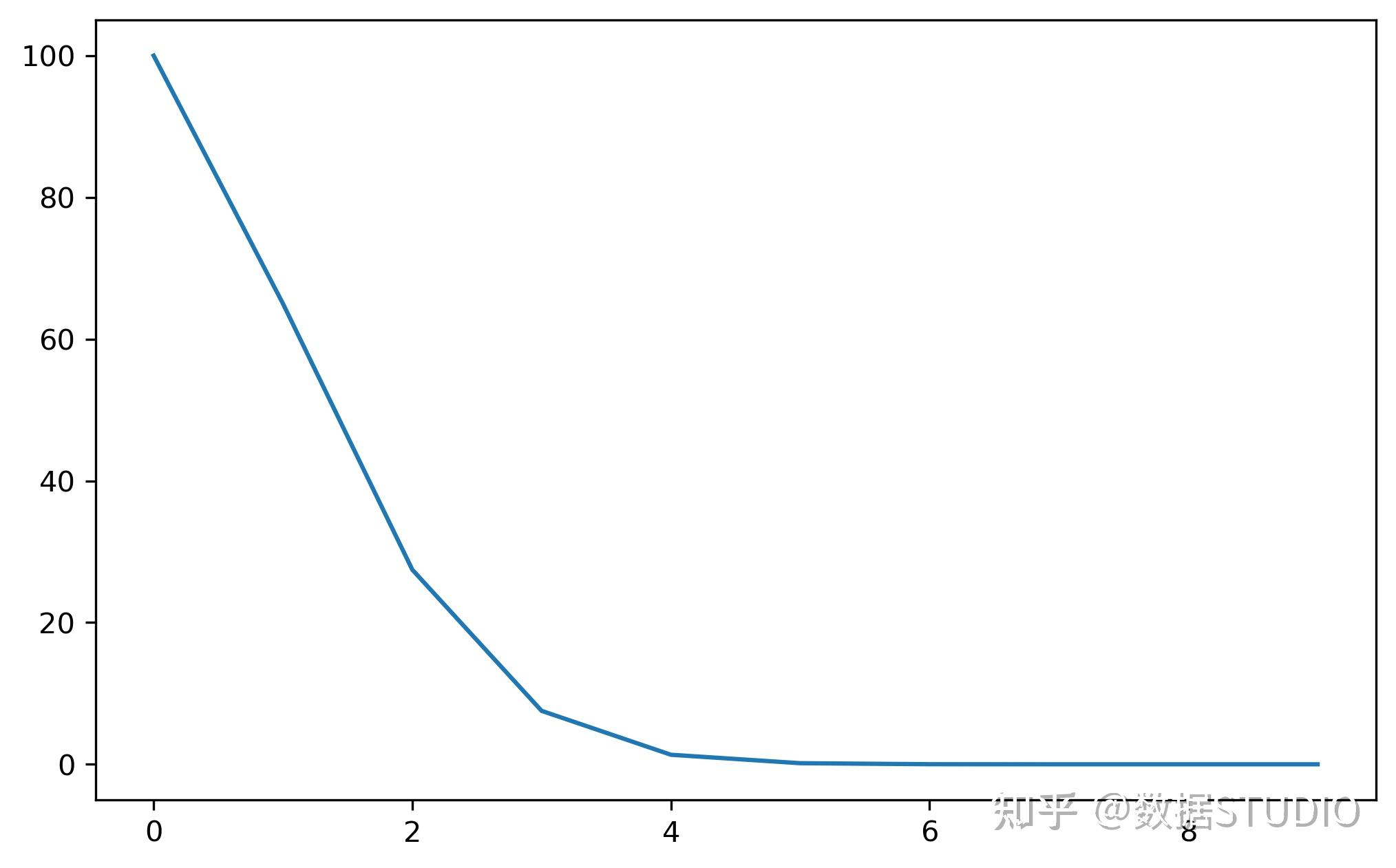
将每个参数组的学习率乘以指定函数中给定的因子。当last_epoch=-1时,将初始lr设置为初始值。
torch.optim.lr_scheduler.MultiplicativeLR(optimizer,
lr_lambda,
last_epoch=-1,
verbose=False,)
参数同上。
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=100)
lmbda = lambda epoch: 0.65 ** epoch
scheduler = torch.optim.lr_scheduler.MultiplicativeLR(optimizer, lr_lambda=lmbda)
lrs = []
for i in range(10):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor=",0.95," , Learning Rate=",optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(range(10),lrs)
每一个步长时期,每个参数组的学习速率以伽马衰减。请注意,这种衰减可能与这个调度程序外部对学习速率的其他改变同时发生。
torch.optim.lr_scheduler.StepLR(optimizer, step_size,
gamma=0.1, last_epoch=-1,
verbose=False)
等间隔调整学习率,每次调整为 lr*gamma,调整间隔为step_size。
step_size(int):学习率调整步长,每经过step_size,学习率更新一次。gamma(float):学习率调整倍数。last_epoch(int):上一个epoch数,这个变量用于指示学习率是否需要调整。当last_epoch符合设定的间隔时就会调整学习率。当设置为-1时,学习率设置为初始值。
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=100)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=2, gamma=0.1)
lrs = []
for i in range(10):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor=",0.1 if i!=0 and i%2!=0 else 1," , Learning Rate=",optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(range(10),lrs)
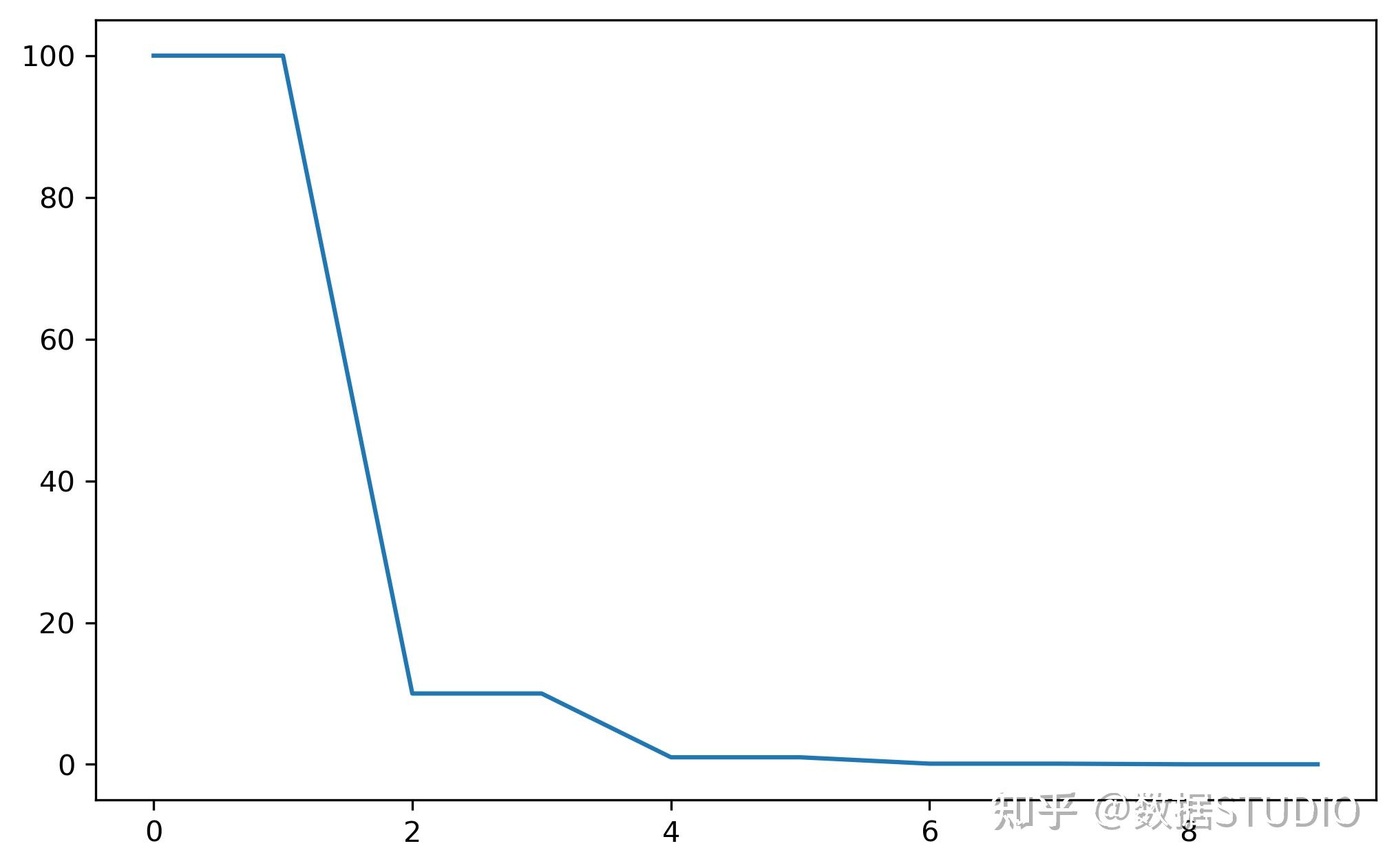
当前epoch数满足设定值时,调整学习率。这个方法适合后期调试使用,观察loss曲线,为每个实验制定学习率调整时期[1]。
milestones(list):一个包含epoch索引的list,列表中的每个索引代表调整学习率的epoch。list中的值必须是递增的。 如[20, 50, 100]表示在epoch为20, 50,100时调整学习率。gamma(float):学习率调整倍数。last_epoch(int):上一个epoch数,这个变量用于指示学习率是否需要调整。当last_epoch符合设定的间隔时就会调整学习率。当设置为-1时,学习率设置为初始值。
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=100)
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[6,8,9], gamma=0.1)
lrs = []
for i in range(10):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor=",0.1 if i in[6,8,9]else 1," , Learning Rate=",optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(range(10),lrs)
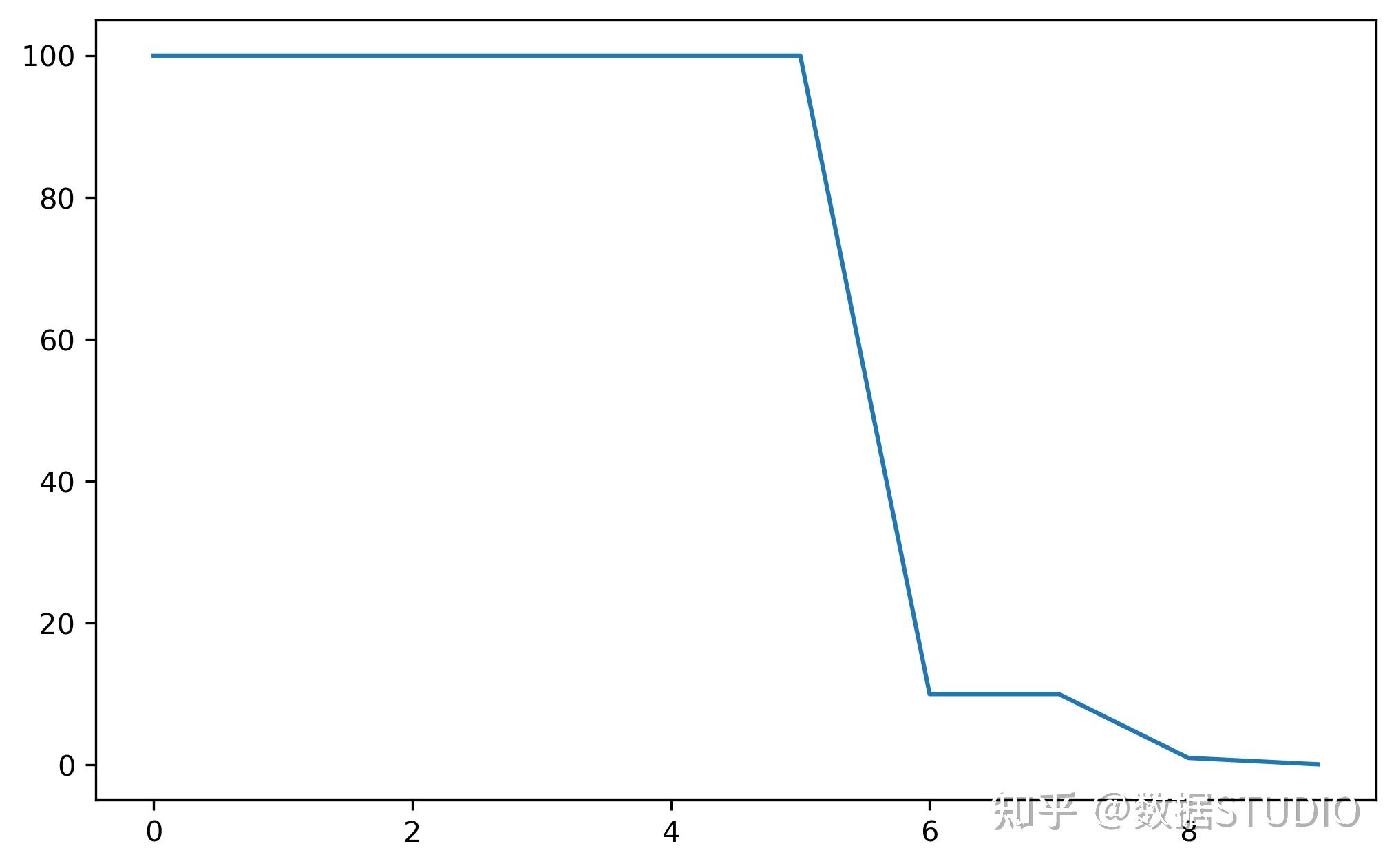
按指数衰减调整学习率。每一个epoch以伽马衰减每个参数组的学习速率。
torch.optim.lr_scheduler.ExponentialLR(optimizer,
gamma,
last_epoch=-1,
verbose=False,)
gamma(float):学习率调整倍数。last_epoch(int):上一个epoch数,这个变量用于指示学习率是否需要调整。当last_epoch符合设定的间隔时就会调整学习率。当设置为-1时,学习率设置为初始值。
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=100)
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.1)
lrs = []
for i in range(10):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor=",0.1," , Learning Rate=",optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(lrs)
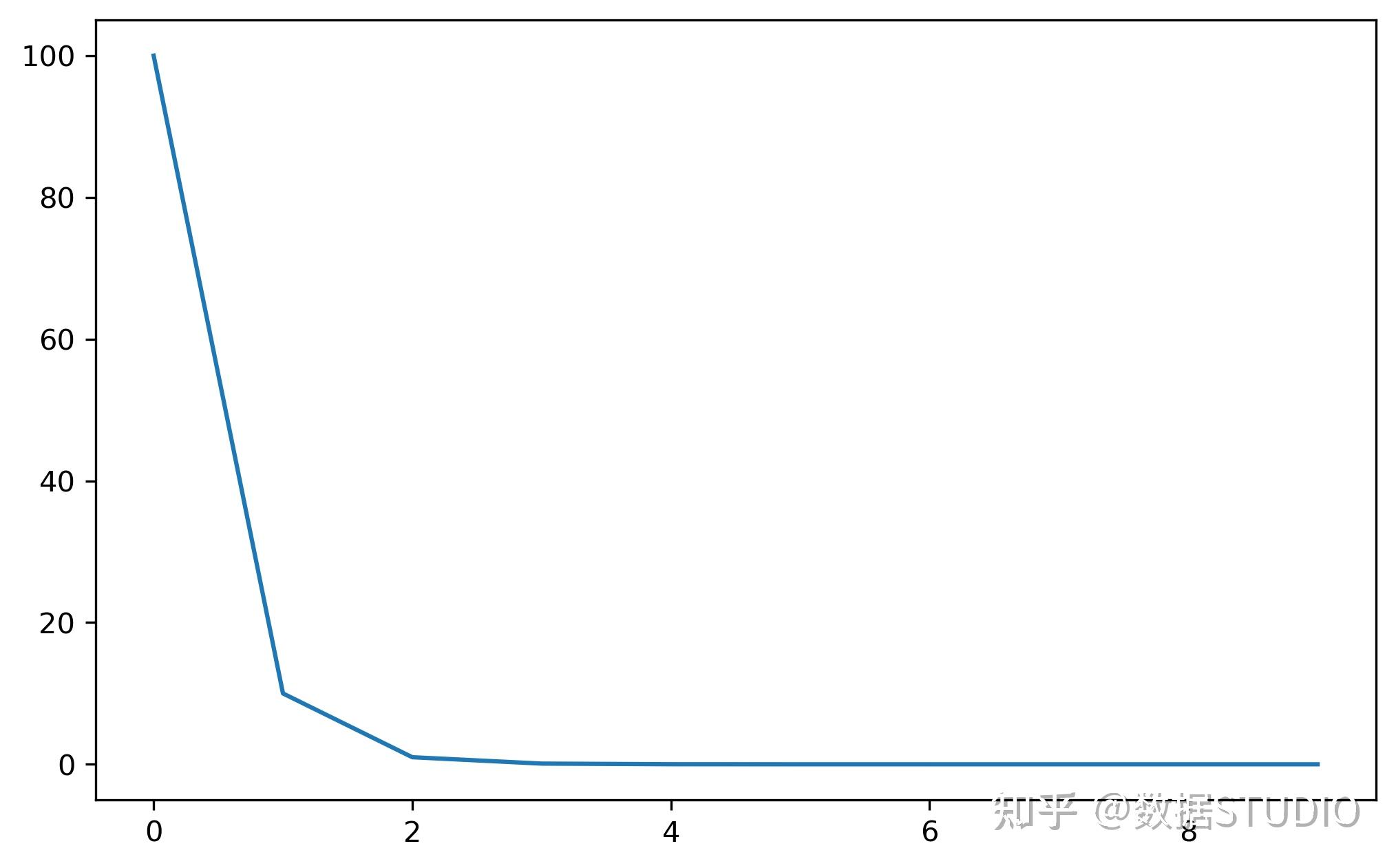
模拟余弦退火曲线调整学习率。
使用余弦退火计划设置每个参数组的学习速率。
注意,因为调度是递归定义的,所以学习速率可以在这个调度程序之外被其他操作符同时修改。如果学习速率由该调度器单独设置,则每一步的学习速率为:
该方法已在SGDR被提出:带温重启的随机梯度下降中提出。请注意,这只实现了SGDR的余弦退火部分,而不是重启。
https://arxiv.org/abs/1608.03983
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=100)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=10, eta_min=0)
lrs = []
for i in range(100):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor=",i," , Learning Rate=",optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(lrs)
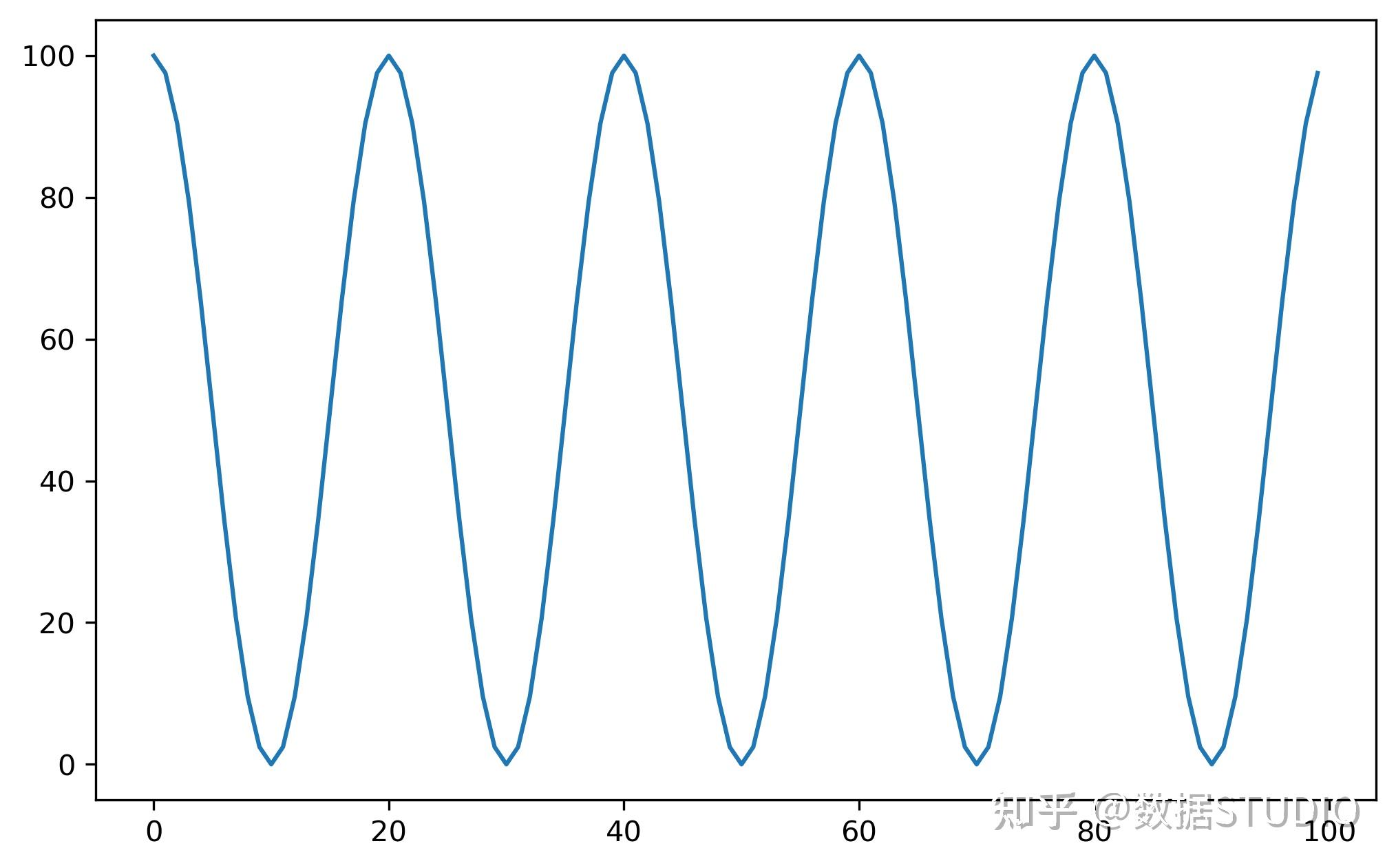
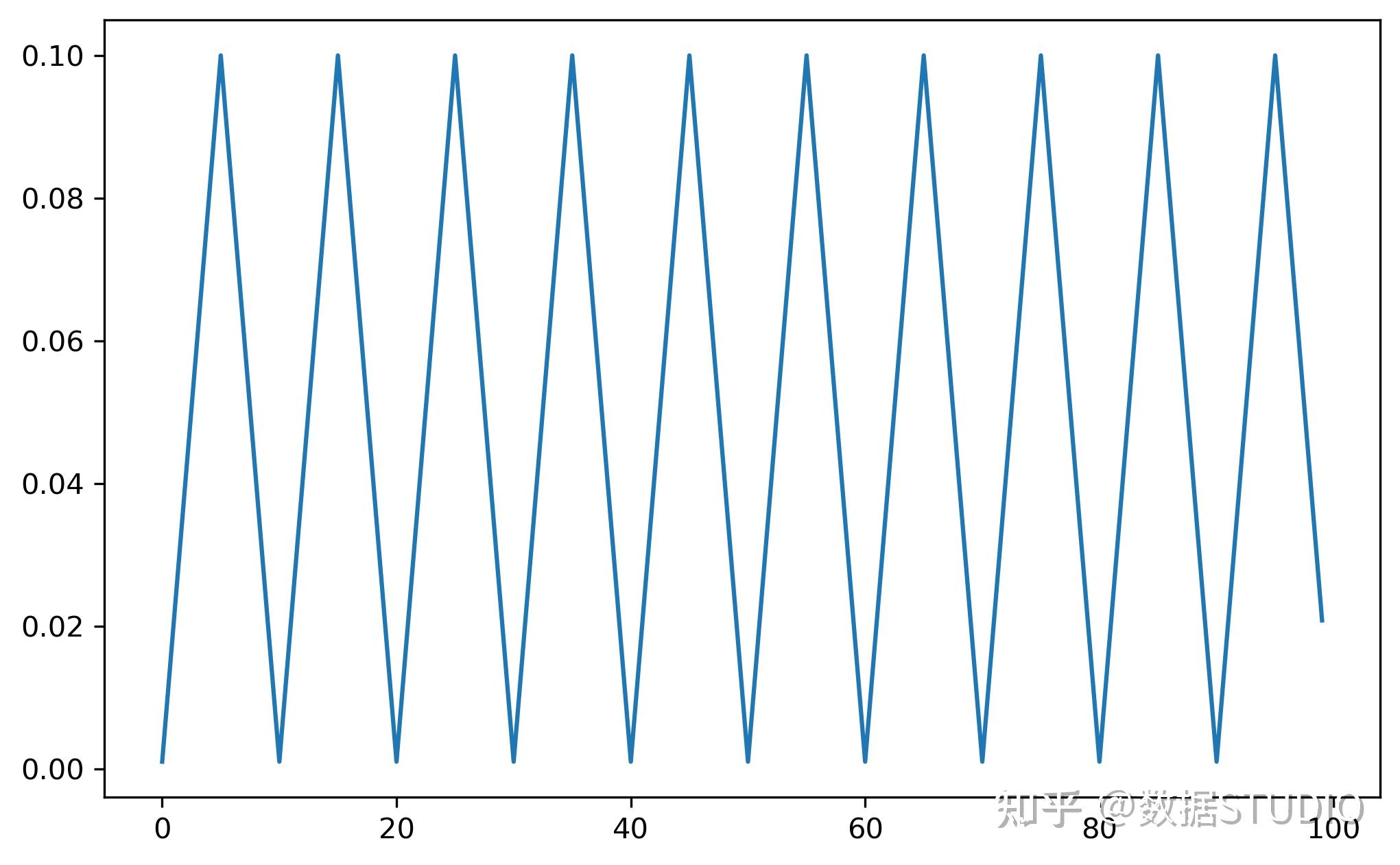
Cyclical Learning Rates for Training Neural Networks 学习率周期性变化。
base_lr(float or list):循环中学习率的下边界。max_lr(floatorlist):循环中学习率的上边界。tep_size_up(int):学习率上升的步数。step_size_down(int):学习率下降的步数。mode(str):{triangular, triangular2, exp_range}中的一个。默认: 'triangular'。gamma(float):在mode='exp_range'时,gamma**(cycle iterations), 默认:1.0(下图4)。scale_fn:自定义的scaling policy,通过只包含有1个参数的lambda函数定义。0 <=scale_fn(x) <=1 for all x >=0.默认:None。如果定义了scale_fn, 则忽略 mode参数last_epoch(int):上一个epoch数,这个变量用于指示学习率是否需要调整。当last_epoch符合设定的间隔时就会调整学习率。当设置为-1时,学习率设置为初始值。
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
scheduler = torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr=0.001, max_lr=0.1,step_size_up=5,mode="triangular")
lrs = []
for i in range(100):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor=",i," , Learning Rate=",optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(lrs)
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
scheduler = torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr=0.001, max_lr=0.1,step_size_up=5,mode="triangular2")
lrs = []
for i in range(100):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor=",i," , Learning Rate=",optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(lrs)

model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=100)
scheduler = torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr=0.001,
max_lr=0.1,step_size_up=5,
mode="exp_range",gamma=0.85)
lrs = []
for i in range(100):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor=",i," , Learning Rate=",optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(lrs)
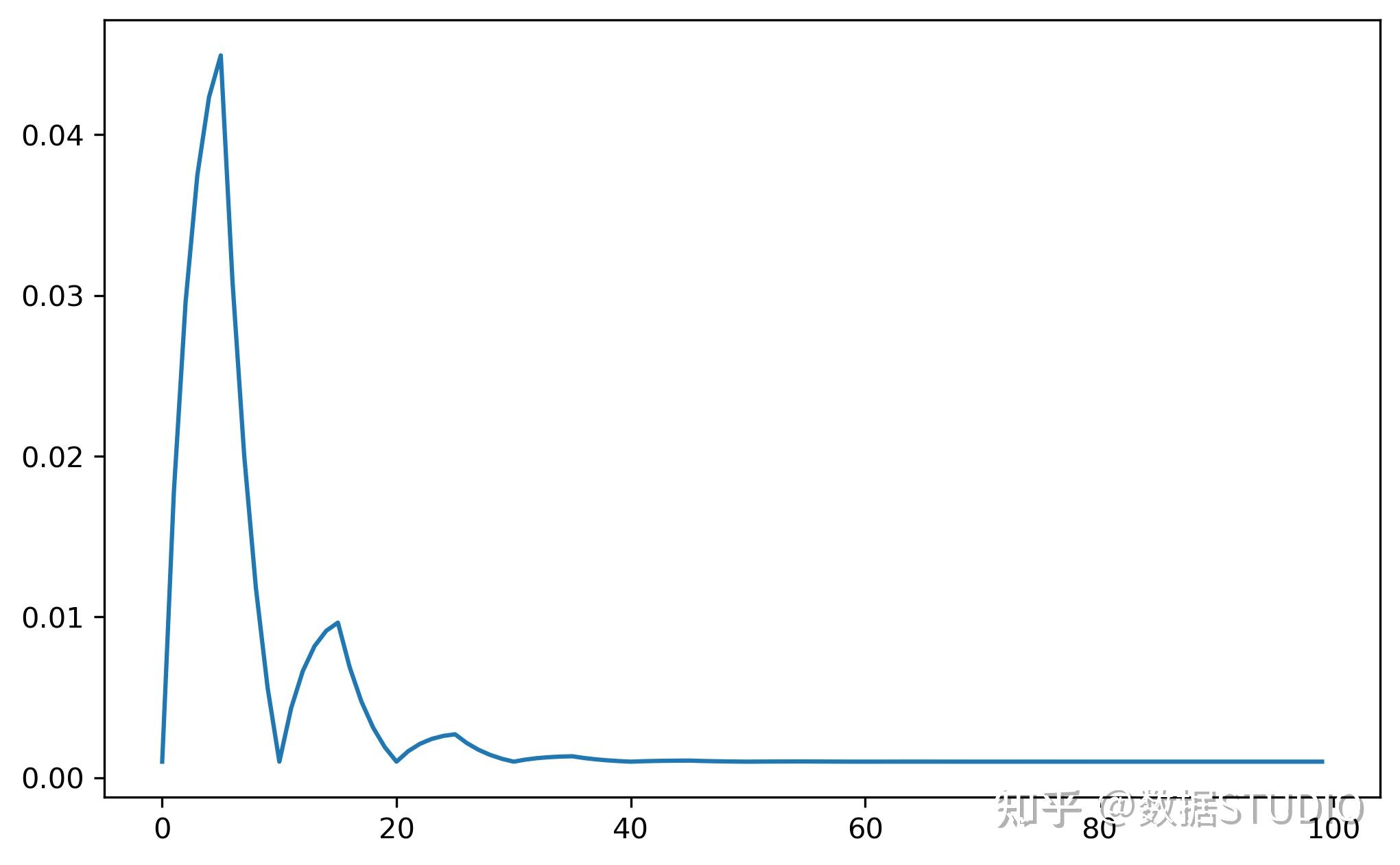
CLR(如上图所示)不是单调地降低训练过程中的学习率,而是让学习率在设定好地最大值与最小值之间往复变化,文中提出CLR能够work的原因在于两点:
- CLR里面增大学习率的过程可以帮助损失函数值逃离鞍点;
- 最优的学习率会在设定好的最大值与最小值之间,最优学习率附近的值在整个训练过程中会被一直使用到。stepsize一般设置为
的2-10倍,一个cycle包括2个stepsize;
base_lr一般设置为max_lr的1/3或者1/4。一般当学习率回到base_lr时使训练结束。
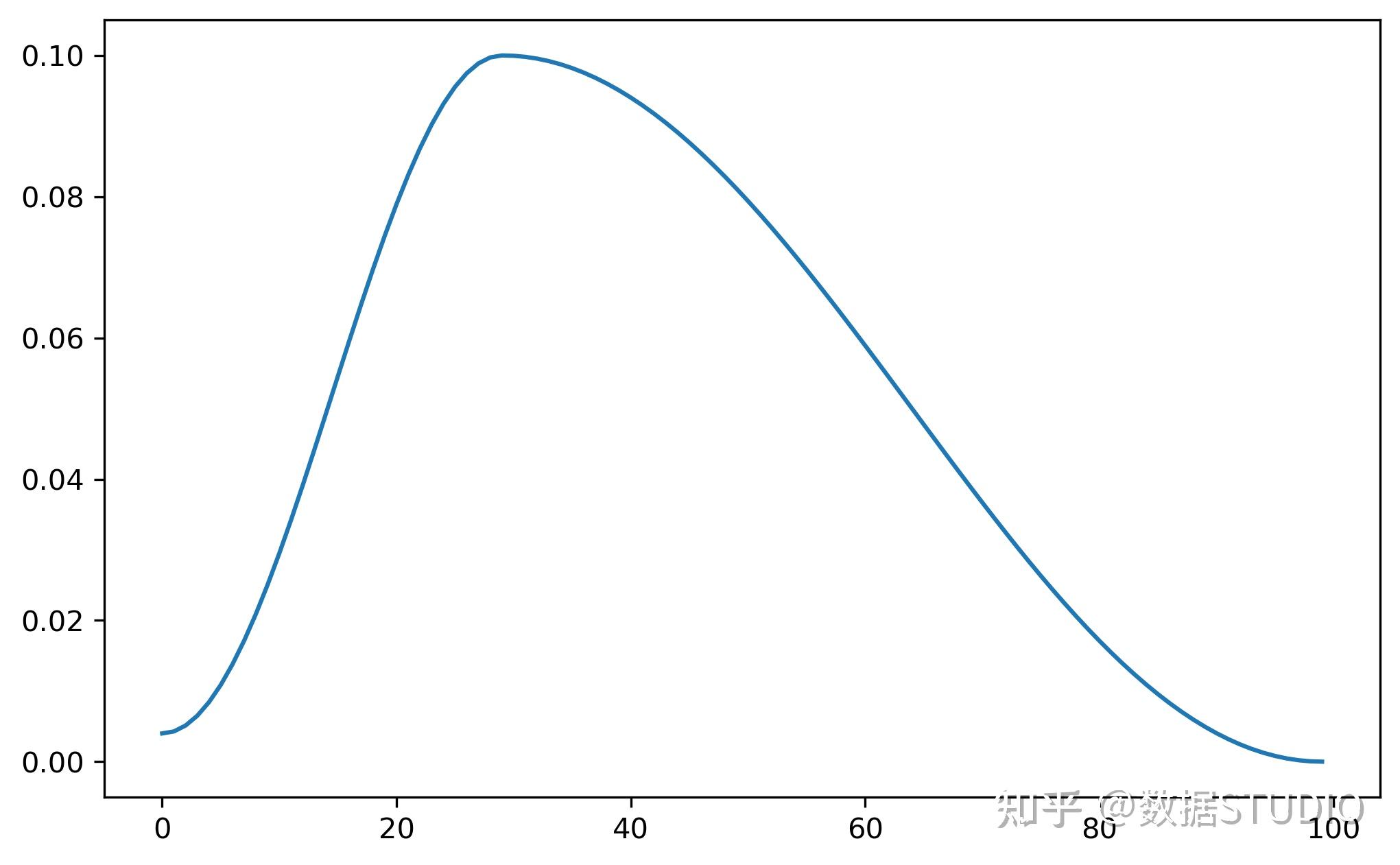
在CLR的基础上,"1cycle"是在整个训练过程中只有一个cycle,学习率首先从初始值上升至max_lr,之后从max_lr下降至低于初始值的大小。和CosineAnnealingLR不同,OneCycleLR一般每个batch后调用一次
根据 "1cycle学习速率策略" 设置各参数组的学习速率。1cycle策略将学习率从初始学习率调整到最大学习率,然后从最大学习率调整到远低于初始学习率的最小学习率。这种策略最初是在论文《Convergence: Very Fast Training of Neural Networks Using Large Learning Rates.超收敛:使用大学习速率的神经网络的快速训练》中描述的。
"1cycle学习速率策略" 在每批学习后会改变学习速率。Step应该在一个批处理被用于培训之后调用。
torch.optim.lr_scheduler.OneCycleLR(
optimizer, # 优化器
max_lr, # 学习率最大值
total_steps=None, epochs=None, steps_per_epoch=None, # 总step次数
pct_start=0.3, anneal_strategy='cos', # 学习率上升的部分step数量的占比
cycle_momentum=True, base_momentum=0.85, max_momentum=0.95,
div_factor=25.0, # 初始学习率=max_lr / div_factor
final_div_factor=10000.0, # 最终学习率=初始学习率 / final_div_factor
three_phase=False, last_epoch=-1, verbose=False)
- max_lr:最大学习率
- total_steps:迭代次数
- div_factor:初始学习率=max_lr / div_factor
- final_div_factor:最终学习率=初始学习率 / final_div_factor
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
scheduler = torch.optim. \\
lr_scheduler.OneCycleLR(
optimizer, max_lr=0.1,
steps_per_epoch=10,
epochs=10)
lrs = []
for i in range(100):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor=",i," , Learning Rate=",optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(lrs)
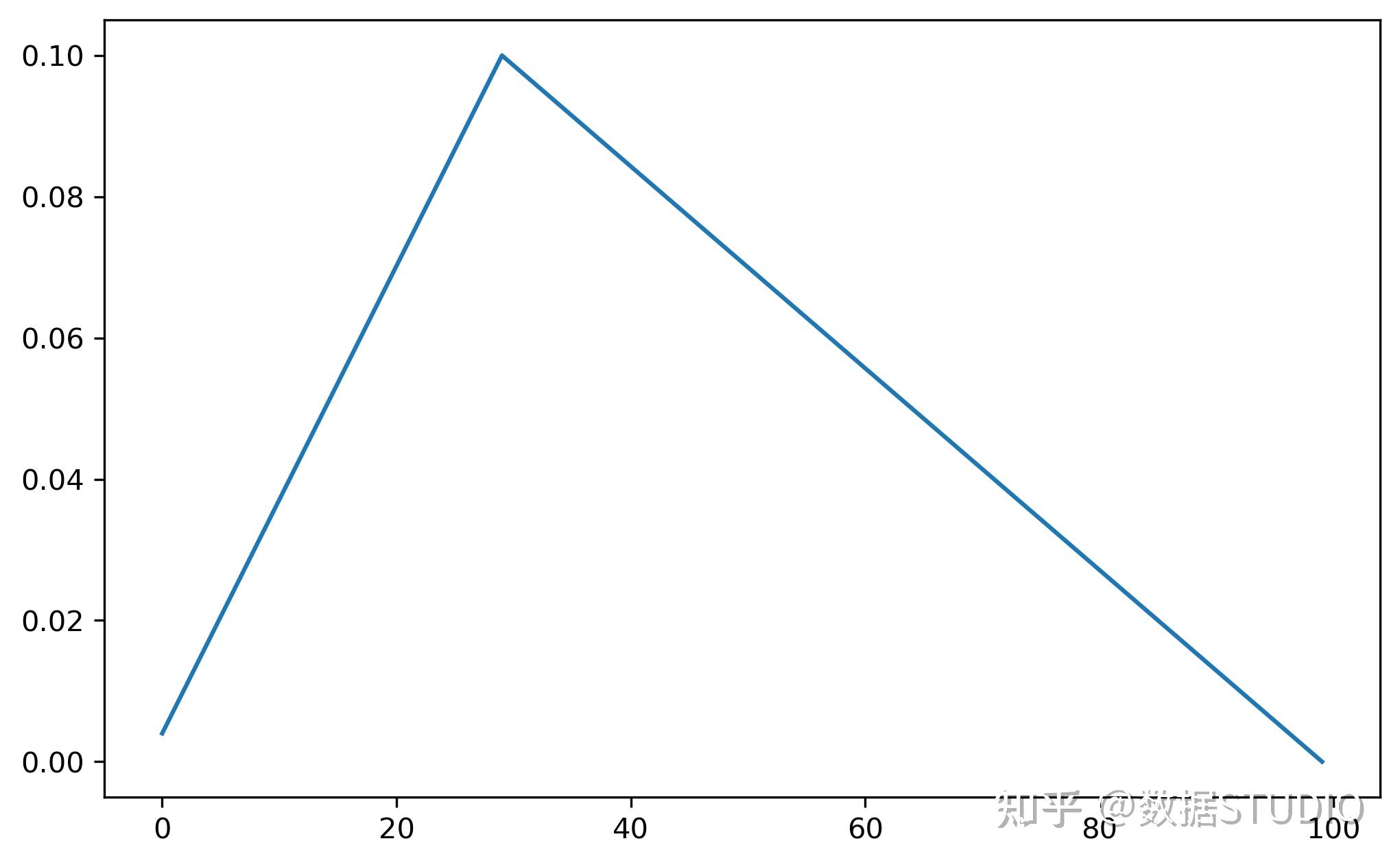
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
scheduler = torch.optim. \\
lr_scheduler.OneCycleLR(
optimizer, max_lr=0.1,
steps_per_epoch=10,
epochs=10,
anneal_strategy='linear')
lrs = []
for i in range(100):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor=",i," , Learning Rate=",optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(lrs)
Warm restart的模拟退火学习率调整曲线 使用余弦退火计划设置每个参数组的学习速率,并在 Ti epoch 后重启。
T_0(int):第一次restart时epoch的数值。T_mult(int):每次restart后,学习率restart周期增加因子。。
eta_min(float):最小的学习率,默认值为0。last_epoch(int):上一个epoch数,这个变量用于指示学习率是否需要调整。当last_epoch符合设定的间隔时就会调整学习率。当设置为-1时,学习率设置为初始值。
T_0=10, T_mult=1, eta_min=0.001,
import torch
import matplotlib.pyplot as plt
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
lr_sched = torch.optim. \\
lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=10,
T_mult=1,
eta_min=0.001,
last_epoch=-1)
lrs = []
for i in range(100):
lr_sched.step()
lrs.append(
optimizer.param_groups[0]["lr"]
)
plt.plot(lrs)
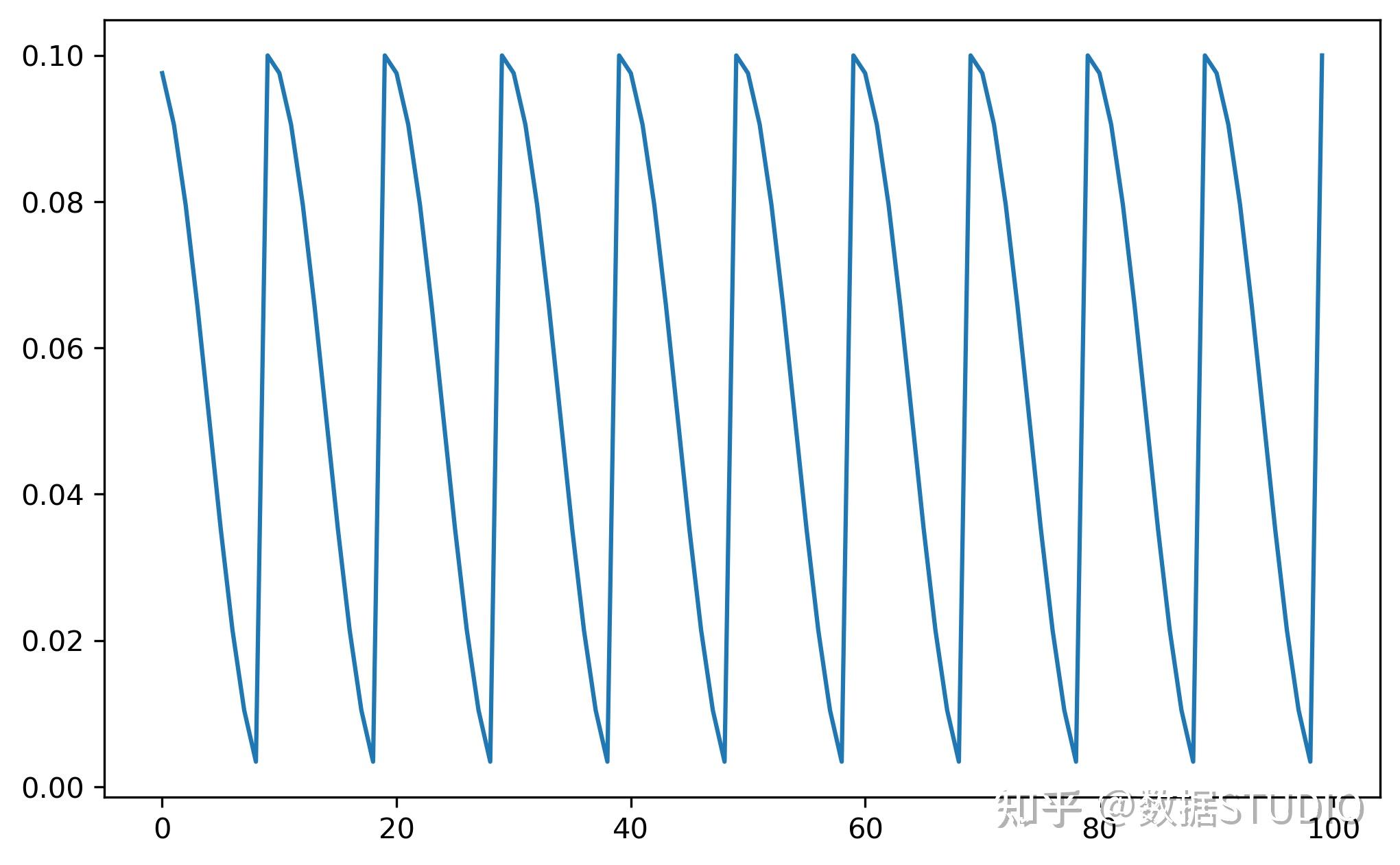
T_0=10, T_mult=2, eta_min=0.01,
import torch
import matplotlib.pyplot as plt
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
lr_sched = torch.optim. \\
lr_scheduler.CosineAnnealingWarmRestarts(optimizer,
T_0=10, T_mult=2,
eta_min=0.01,
last_epoch=-1)
lrs = []
for i in range(300):
lr_sched.step()
lrs.append(
optimizer.param_groups[0]["lr"]
)
plt.plot(lrs)
[1]pytorch: https://pytorch.org/docs/stable/optim.html
[2]https://www.kaggle.com/code/isbhargav/guide-to-pytorch-learning-rate-scheduling/notebook
欢迎转载分享,请在文章中注明作者和原文链接,感谢您对知识的尊重和对本文的肯定。
原文作者:数据STUDIO(知乎ID)
原文链接:https://zhuanlan.zhihu.com/p/528894465
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处,侵权转载将追究相关责任
torch.optim.lr_scheduler 模块提供了一些根据 epoch 训练次数来调整学习率(learning rate)的方法。一般情况下我们会设置随着 epoch 的增大而逐渐减小学习率从而达到更好的训练效果。
而 torch.optim.lr_scheduler.ReduceLROnPlateau 则提供了基于训练中某些测量值使学习率动态下降的方法。学习率的调整应该放在optimizer更新之后,下面是一个参考蓝本:
>>> scheduler = ...
>>> for epoch in range(100):
>>> train(...)
>>> validate(...)
>>> scheduler.step()注意: 在PyTorch 1.1.0之前的版本,学习率的调整(即 scheduler.step())应该被放在optimizer update(即 optimizer.step())之前的。PyTorch 1.1.0之后,则放到后面。
如果我们在 1.1.0 及之后的版本仍然将学习率的调整放在 optimizer update之前,那么 learning rate schedule 的第一个值将会被跳过。所以如果某个代码是在 1.1.0 之前的版本下开发,但现在移植到 1.1.0及之后的版本运行,发现效果变差,需要检查一下是否将scheduler.step()放在了optimizer.step()之前。
为了了解lr_scheduler,我们先以Adam()为例了解一下优化器(所有optimizers都继承自torch.optim.Optimizer类):
语法:
class torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)参数:
- params (iterable):需要优化的网络参数,传进来的网络参数必须是Iterable(官网对这个参数用法讲的不太清楚,下面有例子清楚的说明param具体用法)。
- 如果优化一个网络,网络的每一层看做一个parameter group,一整个网络就是parameter groups(一般给赋值为net.parameters()),补充一点,net.parameters()函数返回的parameter groups实际上是一个变成了generator的字典;
- 如果同时优化多个网络,有两种方法:
- 将多个网络的参数合并到一起,当成一个网络的参数来优化(一般赋值为[*net_1.parameters(), *net_2.parameters(), ..., *net_n.parameters()]或itertools.chain(net_1.parameters(), net_2.parameters(), ..., net_n.parameters()));
- 当成多个网络优化,这样可以很容易的让多个网络的学习率各不相同(一般赋值为[{'params': net_1.parameters()},{'params': net_2.parameters()}, ...,{'params': net_n.parameters()})。
- lr (float, optional):学习率;
- betas (Tuple[float, float], optional) – coefficients used for computing running averages of gradient and its square (default: (0.9, 0.999));
- eps (float, optional) – term added to the denominator to improve numerical stability (default: 1e-8);
- weight_decay (float, optional) – weight decay (L2 penalty) (default: 0);
- amsgrad (boolean, optional) – whether to use the AMSGrad variant of this algorithm from the paper On the Convergence of Adam and Beyond (default: False)。
两个属性:
- optimizer.defaults: 字典,存放这个优化器的一些初始参数,有:'lr', 'betas', 'eps', 'weight_decay', 'amsgrad'。事实上这个属性继承自torch.optim.Optimizer父类;
- optimizer.param_groups:列表,每个元素都是一个字典,每个元素包含的关键字有:'params', 'lr', 'betas', 'eps', 'weight_decay', 'amsgrad',params类是各个网络的参数放在了一起。这个属性也继承自torch.optim.Optimizer父类。
由于上述两个属性都继承自优化器共同的基类,故所有优化器类都有这些属性,并且两者字典中键名相同的元素值也相同(经过lr_scheduler后lr就不同了)。
注意:
lr_scheduler更新optimizer的lr,是更新的optimizer.param_groups[n]['lr'],而不是optimizer.defaults['lr']。
CLASStorch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1, verbose=False)[SOURCE]
Decays the learning rate of each parameter group by gamma every step_size epochs. Notice that such decay can happen simultaneously with other changes to the learning rate from outside this scheduler. When last_epoch=-1, sets initial lr as lr.
Parameters
- optimizer (Optimizer) – Wrapped optimizer.
- step_size (int) – Period of learning rate decay.学习率下降间隔数,若为30,则会在30、60、90…个step时,将学习率调整为lr*gamma。
- gamma (float) – Multiplicative factor of learning rate decay. Default: 0.1. 学习率调整倍数,默认为0.1倍,即下降10倍。
- last_epoch (int) – The index of last epoch. Default: -1.上一个epoch数,这个变量用来指示学习率是否需要调整。当last_epoch符合设定的间隔时,就会对学习率进行调整。当为-1时,学习率设置为初始值。
- verbose (bool) – If True, prints a message to stdout for each update. Default: False.
更新策略:每过step_size个epoch,做一次更新:
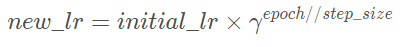
其中 new_lr 是得到的新的学习率,initial_lr 是初始的学习率,step_size 是参数 step_size,γ 是参数gamma。
功能:等间隔调整学习率,调整倍数为gamma倍,调整间隔为step_size。间隔单位是step。需要注意的是,step通常是指epoch,不要弄成iteration了。
optimizer_1 = torch.optim.Adam(model.parameters(), lr = 0.1)
scheduler_1 = torch.optim.lr_scheduler.StepLR(optimizer_1, step_size=3, gamma=0.1)
print(f"初始的学习率:{optimizer_1.defaults['lr']}")
for epoch in range(1,11):
optimizer_1.zero_grad()
optimizer_1.step()
print(f"第 {epoch} epoch的lr:{optimizer_1.param_groups[0]['lr']}")
scheduler_1.step()
#### 结果 ####
# 初始的学习率:0.1
# 第 1 epoch的lr:0.1
# 第 2 epoch的lr:0.1
# 第 3 epoch的lr:0.1
# 第 4 epoch的lr:0.010000000000000002
# 第 5 epoch的lr:0.010000000000000002
# 第 6 epoch的lr:0.010000000000000002
# 第 7 epoch的lr:0.0010000000000000002
# 第 8 epoch的lr:0.0010000000000000002
# 第 9 epoch的lr:0.0010000000000000002
# 第 10 epoch的lr:0.00010000000000000003CLASStorch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1, verbose=False)[SOURCE]
Decays the learning rate of each parameter group by gamma once the number of epoch reaches one of the milestones. Notice that such decay can happen simultaneously with other changes to the learning rate from outside this scheduler. When last_epoch=-1, sets initial lr as lr.
Parameters
- optimizer (Optimizer) – Wrapped optimizer.
- milestones (list) – List of epoch indices. Must be increasing.一个list,每一个元素代表何时调整学习率,list元素必须是递增的。如 milestones=[30,80,120]
- gamma (float) – Multiplicative factor of learning rate decay. Default: 0.1.
- last_epoch (int) – The index of last epoch. Default: -1.
- verbose (bool) – If True, prints a message to stdout for each update. Default: False.
其它和2.1基本相同。
功能:按设定的间隔调整学习率。这个方法适合后期调试使用,观察loss曲线,为每个实验定制学习率调整时机。
optimizer_1 = torch.optim.Adam(model.parameters(), lr = 0.1)
scheduler_1 = torch.optim.lr_scheduler.MultiStepLR(optimizer_1, milestones=[3,8], gamma=0.1)
print(f"初始的学习率:{optimizer_1.defaults['lr']}")
for epoch in range(1,11):
optimizer_1.zero_grad()
optimizer_1.step()
print(f"第 {epoch} epoch的lr:{optimizer_1.param_groups[0]['lr']}")
scheduler_1.step()
#### 结果 #### -- 根据milestones 设置在哪一步进行衰减
初始的学习率:0.1
第 1 epoch的lr:0.1
第 2 epoch的lr:0.1
第 3 epoch的lr:0.1
第 4 epoch的lr:0.010000000000000002
第 5 epoch的lr:0.010000000000000002
第 6 epoch的lr:0.010000000000000002
第 7 epoch的lr:0.010000000000000002
第 8 epoch的lr:0.010000000000000002
第 9 epoch的lr:0.0010000000000000002
第 10 epoch的lr:0.0010000000000000002CLASStorch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1, verbose=False)[SOURCE]
Decays the learning rate of each parameter group by gamma every epoch. When last_epoch=-1, sets initial lr as lr.
Parameters
- optimizer (Optimizer) – Wrapped optimizer.
- gamma (float) – Multiplicative factor of learning rate decay.学习率调整倍数的底,指数为epoch
- last_epoch (int) – The index of last epoch. Default: -1.
- verbose (bool) – If True, prints a message to stdout for each update. Default: False.
功能:按指数衰减调整学习率,调整公式:
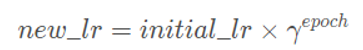
optimizer_1 = torch.optim.Adam(model.parameters(), lr = 0.1)
scheduler_1 = torch.optim.lr_scheduler.ExponentialLR(optimizer_1, gamma=0.1)
print(f"初始的学习率:{optimizer_1.defaults['lr']}")
for epoch in range(1,11):
optimizer_1.zero_grad()
optimizer_1.step()
print(f"第 {epoch} epoch的lr:{optimizer_1.param_groups[0]['lr']}")
scheduler_1.step()
#### 结果 #### --
初始的学习率:0.1
第 1 epoch的lr:0.1
第 2 epoch的lr:0.010000000000000002
第 3 epoch的lr:0.0010000000000000002
第 4 epoch的lr:0.00010000000000000003
第 5 epoch的lr:1.0000000000000004e-05
第 6 epoch的lr:1.0000000000000004e-06
第 7 epoch的lr:1.0000000000000005e-07
第 8 epoch的lr:1.0000000000000005e-08
第 9 epoch的lr:1.0000000000000005e-09
第 10 epoch的lr:1.0000000000000006e-10CLASS torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1, verbose=False)
- optimizer (Optimizer) – Wrapped optimizer.
- T_max (int) – Maximum number of iterations. 一次学习率周期的迭代次数,即T_max个epoch之后重新设置学习率。
- eta_min (float) – Minimum learning rate. Default: 0. 最小学习率,即在一个周期中,学习率最小会下降到eta_min,默认值为0
- last_epoch (int) – The index of last epoch. Default: -1.
- verbose (bool) – If True, prints a message to stdout for each update. Default: False.
功能:让 lr 随着 epoch 的变化图类似于cos:
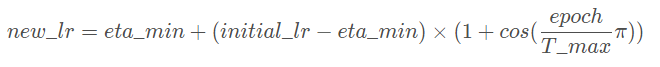
以余弦函数为周期,并在每个周期最大值时重新设置学习率。具体如下图所示
详细请阅读论文《 SGDR: Stochastic Gradient Descent with Warm Restarts》(ICLR-2017):https://arxiv.org/abs/1608.03983
optimizer_1 = torch.optim.Adam(model.parameters(), lr = 0.1)
scheduler_1 = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer_1, T_max=4)
print(f"初始的学习率:{optimizer_1.defaults['lr']}")
for epoch in range(1,16):
optimizer_1.zero_grad()
optimizer_1.step()
print(f"第 {epoch} epoch的lr:{optimizer_1.param_groups[0]['lr']}")
scheduler_1.step()
#### 结果 #### --
初始的学习率:0.1
第 1 epoch的lr:0.1
第 2 epoch的lr:0.08535533905932738
第 3 epoch的lr:0.05
第 4 epoch的lr:0.014644660940672627
第 5 epoch的lr:0.0
第 6 epoch的lr:0.014644660940672622
第 7 epoch的lr:0.05000000000000001
第 8 epoch的lr:0.0853553390593274
第 9 epoch的lr:0.10000000000000003
第 10 epoch的lr:0.0853553390593274
第 11 epoch的lr:0.05000000000000003
第 12 epoch的lr:0.014644660940672672
第 13 epoch的lr:0.0
第 14 epoch的lr:0.014644660940672622
第 15 epoch的lr:0.0499999999999999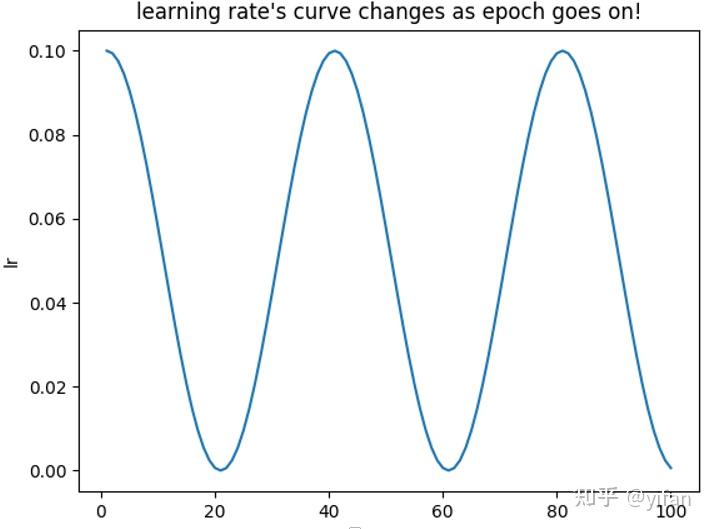
CLASStorch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08, verbose=False)[SOURCE]
Reduce learning rate when a metric has stopped improving. Models often benefit from reducing the learning rate by a factor of 2-10 once learning stagnates. This scheduler reads a metrics quantity and if no improvement is seen for a 'patience' number of epochs, the learning rate is reduced.
Parameters
- optimizer (Optimizer) – Wrapped optimizer.
- mode (str) – One of min, max. In min mode, lr will be reduced when the quantity monitored has stopped decreasing; in max mode it will be reduced when the quantity monitored has stopped increasing. Default: 'min'. 有 min和max两种模式,min表示当指标不再降低(如监测loss),max表示当指标不再升高(如监测accuracy)。
- factor (float) – Factor by which the learning rate will be reduced. new_lr=lr * factor. Default: 0.1. 学习率调整倍数(等同于其它方法的gamma),即学习率更新为 lr=lr * factor
- patience (int) – Number of epochs with no improvement after which learning rate will be reduced. For example, if patience=2, then we will ignore the first 2 epochs with no improvement, and will only decrease the LR after the 3rd epoch if the loss still hasn't improved then. Default: 10. “耐心”,即忍受该指标多少个step不变化,当忍无可忍时,调整学习率。注,可以不是连续5次。
- threshold (float) – Threshold for measuring the new optimum, to only focus on significant changes. Default: 1e-4.配合threshold_mode使用,默认值1e-4。作用是用来控制当前指标与best指标的差异。
- threshold_mode (str) – One of rel, abs. In rel mode, dynamic_threshold=best * ( 1 + threshold ) in 'max' mode or best * ( 1 - threshold ) in min mode. In abs mode, dynamic_threshold=best + threshold in max mode or best - threshold in min mode. Default: 'rel'. 当threshold_mode=rel,并且mode=max时,dynamic_threshold=best * ( 1 + threshold );当threshold_mode=rel,并且mode=min时,dynamic_threshold=best * ( 1 - threshold );当threshold_mode=abs,并且mode=max时,dynamic_threshold=best + threshold ;当threshold_mode=rel,并且mode=max时,dynamic_threshold=best - threshold
- cooldown (int) – Number of epochs to wait before resuming normal operation after lr has been reduced. Default: 0. “冷却时间“,当调整学习率之后,让学习率调整策略冷静一下,让模型再训练一段时间,再重启监测模式。
- min_lr (float or list) – A scalar or a list of scalars. A lower bound on the learning rate of all param groups or each group respectively. Default: 0. 学习率下限,可为float,或者list,当有多个参数组时,可用list进行设置。
- eps (float) – Minimal decay applied to lr. If the difference between new and old lr is smaller than eps, the update is ignored. Default: 1e-8. 学习率衰减的最小值,当学习率变化小于eps时,则不调整学习率。
- verbose (bool) – If True, prints a message to stdout for each update. Default: False. 是否打印学习率信息, print('Epoch{:5d}: reducing learning rate' ' of group{}to{:.4e}.'.format(epoch, i, new_lr))
功能:当某指标不再变化(下降或升高),调整学习率,这是非常实用的学习率调整策略。例如,当验证集的loss不再下降时,进行学习率调整;或者监测验证集的accuracy,当accuracy不再上升时,则调整学习率。
optimizer_1 = torch.optim.Adam(model.parameters(), lr = 0.1)
scheduler_1 = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer_1, mode='min', factor=0.1, patience=3)
print(f"初始的学习率:{optimizer_1.defaults['lr']}")
for epoch in range(1,16):
optimizer_1.zero_grad()
optimizer_1.step()
print(f"第 {epoch} epoch的lr:{optimizer_1.param_groups[0]['lr']}")
scheduler_1.step(2)
#### 结果 #### --
初始的学习率:0.1
第 1 epoch的lr:0.1
第 2 epoch的lr:0.1
第 3 epoch的lr:0.1
第 4 epoch的lr:0.1
第 5 epoch的lr:0.1
第 6 epoch的lr:0.010000000000000002
第 7 epoch的lr:0.010000000000000002
第 8 epoch的lr:0.010000000000000002
第 9 epoch的lr:0.010000000000000002
第 10 epoch的lr:0.0010000000000000002
第 11 epoch的lr:0.0010000000000000002
第 12 epoch的lr:0.0010000000000000002
第 13 epoch的lr:0.0010000000000000002
第 14 epoch的lr:0.00010000000000000003
第 15 epoch的lr:0.00010000000000000003CLASStorch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1, verbose=False)[SOURCE]
Sets the learning rate of each parameter group to the initial lr times a given function. When last_epoch=-1, sets initial lr as lr.
Parameters
- optimizer (Optimizer) – Wrapped optimizer.
- lr_lambda (function or list) – A function which computes a multiplicative factor given an integer parameter epoch, or a list of such functions, one for each group in optimizer.param_groups. 一个计算学习率调整倍数的函数,输入通常为step,当有多个参数组时,设为list。
- last_epoch (int) – The index of last epoch. Default: -1.
- verbose (bool) – If True, prints a message to stdout for each update. Default: False.
功能:为不同参数组设定不同学习率调整策略。调整规则为,lr=base_lr * lmbda(self.last_epoch) 。
ignored_params = list(map(id, model.linear2.parameters()))
base_params = filter(lambda p: id(p) not in ignored_params, model.parameters())
optimizer = torch.optim.SGD([
{'params': base_params},
{'params': model.linear2.parameters(), 'lr': 0.1}], 0.001, momentum=0.9, weight_decay=1e-4)
lambda1 = lambda epoch: epoch // 3
lambda2 = lambda epoch: 0.95 ** epoch
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=[lambda1, lambda2])
for epoch in range(20):
print('epoch: ', epoch, 'lr: ', scheduler.get_lr())
scheduler.step()
#### 结果 #### --
epoch: 0 lr: [0.0, 0.1]
epoch: 1 lr: [0.0, 0.095]
epoch: 2 lr: [0.0, 0.09025]
epoch: 3 lr: [0.001, 0.0857375]
epoch: 4 lr: [0.001, 0.081450625]
epoch: 5 lr: [0.001, 0.07737809374999999]
epoch: 6 lr: [0.002, 0.07350918906249998]
epoch: 7 lr: [0.002, 0.06983372960937498]
epoch: 8 lr: [0.002, 0.06634204312890622]
epoch: 9 lr: [0.003, 0.0630249409724609]
epoch: 10 lr: [0.003, 0.05987369392383787]
epoch: 11 lr: [0.003, 0.05688000922764597]
epoch: 12 lr: [0.004, 0.05403600876626367]
epoch: 13 lr: [0.004, 0.051334208327950485]
epoch: 14 lr: [0.004, 0.04876749791155296]
epoch: 15 lr: [0.005, 0.046329123015975304]
epoch: 16 lr: [0.005, 0.04401266686517654]
epoch: 17 lr: [0.005, 0.04181203352191771]
epoch: 18 lr: [0.006, 0.039721431845821824]
epoch: 19 lr: [0.006, 0.03773536025353073]为什么第一个参数组的学习率会是0呢? 来看看学习率是如何计算的。
第一个参数组的初始学习率设置为0.001, lambda1=lambda epoch: epoch // 3,
第1个epoch时,由lr=base_lr * lmbda(self.last_epoch),可知道 lr=0.001 * (0//3) ,又因为1//3等于0,所以导致学习率为0。
第二个参数组的学习率变化,就很容易看啦,初始为0.1,lr=0.1 * 0.95^epoch ,当epoch为0时,lr=0.1 ,epoch为1时,lr=0.1*0.95。
Pytorch提供了六种学习率调整方法,可分为三大类,分别是
- 有序调整; 依一定规律有序进行调整,这一类是最常用的,分别是等间隔下降(Step),按需设定下降间隔(MultiStep),指数下降(Exponential)和CosineAnnealing。这四种方法的调整时机都是人为可控的,也是训练时常用到的。
- 自适应调整; 依训练状况伺机调整,这就是ReduceLROnPlateau方法。该法通过监测某一指标的变化情况,当该指标不再怎么变化的时候,就是调整学习率的时机,因而属于自适应的调整。
- 自定义调整。 自定义调整,Lambda。Lambda方法提供的调整策略十分灵活,我们可以为不同的层设定不同的学习率调整方法,这在fine-tune中十分有用,我们不仅可为不同的层设定不同的学习率,还可以为其设定不同的学习率调整策略,简直不能更棒!
在pytorch中,学习率的更新是通过scheduler.step(),而我们知道影响学习率的一个重要参数就是epoch,而epoch与scheduler.step()是如何关联的呢?这就需要看源码了。
源码在torch/optim/lr_scheduler.py,step()方法在_LRScheduler类当中,该类作为所有学习率调整的基类,其中定义了一些基本方法,如现在要介绍的step(),以及最常用的get_lr(),不过get_lr()是一个虚函数,均需要在派生类中重新定义函数。看看step()
def step(self, epoch=None):
if epoch is None:
epoch=self.last_epoch + 1
self.last_epoch=epoch
for param_group, lr in zip(self.optimizer.param_groups, self.get_lr()):
param_group['lr']=lr函数接收变量epoch,默认为None,当为None时,epoch=self.last_epoch + 1。从这里知道,last_epoch是用以记录epoch的。上面有提到last_epoch的初始值是-1。因此,第一个epoch的值为 -1+1=0。接着最重要的一步就是获取学习率,并更新。
由于pytorch是基于参数组的管理方式,这里需要采用for循环对每一个参数组的学习率进行获取及更新。这里需要注意的是get_lr(),get_lr()的功能就是获取当前epoch,该参数组的学习率。
这里以StepLR()为例,介绍get_lr(),请看代码:
def get_lr(self):
return[base_lr * self.gamma ** (self.last_epoch // self.step_size) for base_lr in self.base_lrs]由于pytorch是基于参数组的管理方式,可能会有多个参数组,因此用for循环,返回的是一个list。list元素的计算方式为
base_lr * self.gamma ** (self.last_epoch // self.step_size)。
看完代码,可以知道,在执行一次scheduler.step()之后,epoch会加1,因此scheduler.step()要放在epoch的for循环当中执行。
- 【pt-00】pytorch如何学习?入门到实践系列
- 配套代码链接gitee
- 官网:https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
- torch.optim.lr_scheduler:调整学习率 https://blog.csdn.net/qyhaill/article/details/103043637
- PyTorch 学习笔记(八):PyTorch的六个学习率调整方法https://blog.csdn.net/u011995719/article/details/89486359
若觉得有用,欢迎 点赞/收藏 ~~~


