面试基础整理--优化器
发布时间:2024-07-01 13:25:22 浏览次数:
梯度是函数变化最快的地方
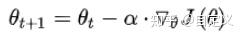
不足:
- 训练速度慢,每一步都要重新调整方向。在大型数据中,每输入一个样本都要进行一次参数更新,且每次迭代都要遍历所有的样本。 会使得训练过程及其缓慢,需要花费很长时间才能得到收敛。
- 容易陷入局部最优。落入鞍点,梯度为0, 使得模型参数不在继续更新
SGD
每次参数更新仅仅选取一个样本,计算一个样本的梯度。
优点:下降速度快,即使样本量很大,也只需要一部分就能迭代到最优解
不足:
- 由于每次迭代不是向着整体最优方向,导致梯度下降波动很大,容易从一个局部最优跳到另一个局部最优--动量
- 学习率选取困难,太高导致收敛时波动太大;太低会导致收敛太慢。且所以参数公用lr
- 容易被困在鞍点
在SGD基础上增加了动量,可以理解为加速度。就像小球,当从山坡滚下没有阻力时加速度会使速度越来越快,遇到阻力速度就会越来越小。动量优化就是在梯度方向不变的情况下,参数更新速度变快,梯度方向改变,更新速度就变慢。
Momentum
思想:在更新时一定程度上保留之前的更新方向。一方面保留之前的梯度方向(一部分),另一方面计算新的方向。
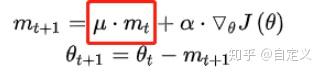
在梯度方向上,如果新方向和原来一样,加速;不一样相当于减速
总之,这种方式可以加速SGD收敛,抑制震荡。
针对于目前机器学习模型的学习率,之前提到的方法要么将学习率设置成常数,要么根据训练次数调节学习率,但是忽略了其他变化的可能,以下的优化方法就考虑了
AdaGrad
适合分布不均或分布不平衡的数据集,对于出现多的类别数据,给予越来越小得学习率,对于出现次数小的类别数据,给予较大的学习率
不足:随着训练,lr趋于0
RMSprop
解决了AdaGrad中学习率下降过快的问题
Adam
相当于Momentum和RMSprop的结合体,既有动量项,又可以自适应学习率
补充:影响梯度下降算法的会是什么呢



